
Coding: Isolate the data not just the endpoint
One of the fairly standard ways of shielding our applications when integrating with other systems is to create a wrapper around it so that all interaction with it is in one place.
As I mentioned in a previous post we have been using the repository pattern to achieve this in our code.
One service which we needed to integrate lately provided data for populating data on drop downs on our UI so the service provided two pieces of data - a Value (which needed to be sent to another service when a certain option was selected) and a Label (which was the value for us to display on the screen).
Our original approach was to pass both bits of the data through the system and we populated the dropdowns such that the value being passed back to the service would be the Value but the value shown to the user would be the Label.
The option part of the drop down list would therefore look like this:
<select>
...
<option value="Value">Label</option>
</select>With the data flowing through our application like so:
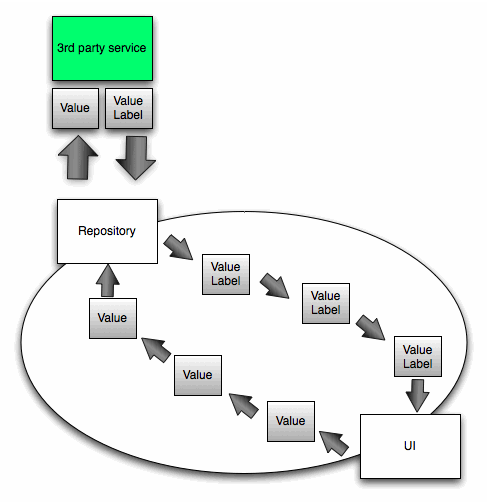
Although this approach worked it made our code really complicated and we were actually passing Value around the code even though our application didn’t care about it at all, only the service did.
A neat re-design idea a couple of my colleagues came up with to was to only pass the Label through the application and then just do a mapping in the Repository from the Label -> Value so we could send the correct value to the service.
The code then became much simpler:
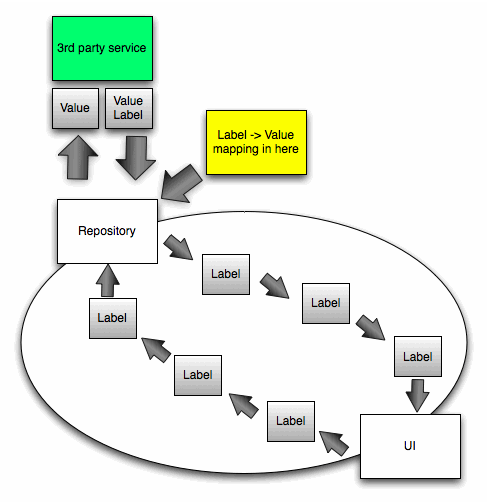
And we had isolated the bit of code that led to the complexity in the first place.
The lesson here for me is that it’s not enough merely to isolate the endpoint, we also need to think about which data our application actually needs and only pass through the data we actually use.
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.