
Coding: Light weight wrapper vs serialisation/deserialisation
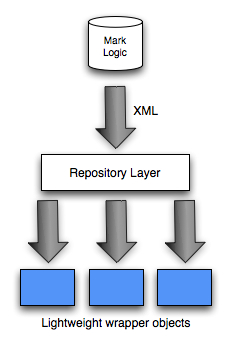
As I’ve mentioned before, we’re making use of a MarkLogic database on the project I’m working on which means that we’re getting quite big XML data structures coming into our application whenever we execute a query.
The normal way that I’ve seen for dealing with external systems would be to create an anti corruption layer where we initialise objects in our system with the required data from the external system.
In this case we’ve decided that approach doesn’t seem to make as much sense because we don’t need to do that much with the data that we get back.
We effectively map straight into a read model where the only logic is some formatting for how the data will be displayed on the page.
The read model objects look a bit like this:
class Content(root : xml.Node) {
def numberOfResults: Int = (root \ "@count").text.toInt
}They are just lightweight wrapper objects and we make use of Scala’s XML support to retrieve the various bits of content onto the page.
The advantage of doing things this way is that it means we have less code to write than we would with the serialisation/deserialisation approach although it does mean that we’re strongly coupled to the data format that our storage mechanism uses.
However, since this is one bit of the architecture which is not going to change it seems to makes sense to accept the leakage of that layer.
So far the approach seems to be working out fine but it’ll be interesting to see how well it holds up if those lightweight wrappers do end up needing to have more logic in them.
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.