
Micro Services: A simple example
In our code base we had the concept of a 'ProductSpeed' with two different constructors which initialised the object in different ways:
public class ProductSpeed {
public ProductSpeed(String name) {
...
}
public ProductSpeed(String name, int order)) {
}
}In the cases where the first constructor was used the order of the product was irrelevant.
When the second constructor was used we did care about it because we wanted to be able sort the products before showing them in a drop down list to the user.
The reason for the discrepancy was that this object was being constructed from data which originated from two different systems and in one the concept of order existed and in the other it didn’t.
What we actually needed was to have two different versions of that object but we probably wouldn’t want to name them 'ProductSpeedForSystem1' and 'ProductSpeedForSystem2'!
In Domain Driven Design terms we actually have the concept of a 'ProductSpeed' but in two different bounded contexts which could just mean that they come under different packages if we’re building everything in one (monolithic) application.
However, we could see from looking at the way 'ProductSpeed' initialised from the second constructor was being used in the application that it didn’t interact with anything else and so could easily be pulled out into its own mini application or micro service.
We’re actually building an API for other systems to interact with and the initial design of the code described above was:
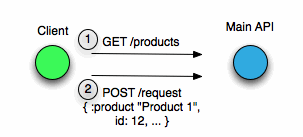
We get a product from the product list (which is sorted based on the ordering described!) and then post a request which includes the product amongst other things.
After we’d pulled out a micro service it looked like this:
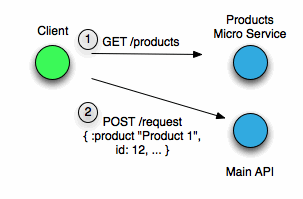
The choice of product is actually a step that you do before you make your request to the main API whereas we’d initially coupled them into the same deployable.
These are the advantages I see from what we’ve done:
-
We can now easily change the underlying data source of the products micro service if we want to since it now has its own schema which we could switch out if necessary.
-
It takes about 5 minutes to populate all the products and we run the script to repopulate the main DB quite frequently. Now products can be loaded separately.
-
Our code is now much simplified!
And some disadvantages:
-
We now have to deploy two jars instead of one so our deployment has become a bit more complicated. My colleague James Lewis points out that we’re effectively pushing the complexity from the application into the infrastructure when we design systems with lots of mini applications doing one thing.
-
Overall I think we have more code since there are some similarities between the objects in both contexts and we’ve now got two versions of each object since they’re deployed separately. My experience is that sharing domain code generally leads to suffering so we’re not doing that.
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.