
neo4j: What question do you want to answer?
Over the past few weeks I’ve been modelling ThoughtWorks project data in neo4j and I realised that the way that I’ve been doing this is by considering what question I want to answer and then building a graph to answer it.
When I first started doing this the main question I wanted to answer was 'how connected are people to each other' which led to me modelling the data like this:

The 'colleagues with' relationship stored information about the project the two people had worked on together and how long they’d worked together.
This design was fine while that was the only question I wanted to answer but after I showed it to a few people it became clear that there were other questions we could ask which would be difficult to answer with it designed this way.
e.g.
-
Which people on project X have I never worked with?
-
Which person has worked for client X for the longest?
-
Which people worked together on the same client if not the same project?
I therefore need to make 'client' and 'project' first class entities in the graph rather than just being there implicitly which favours a design more along these lines:
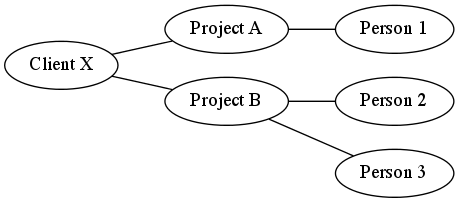
It makes it a little more difficult to answer the initial question about connections between people but opens up the answers to other questions such as the ones detailed above.
I’m still getting used to this way of modelling data but it feels like you’re driven towards designing your data in a way that’s useful to you as opposed to the relational approach where you tend to model relations and then work out what you want to do with the data.
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.