
Book Review: The Signal and the Noise - Nate Silver
Nate Silver is famous for having correctly predicted the winner of all 50 states in the 2012 United States elections and Sid recommended his book so I could learn more about statistics for the A/B tests that we were running.
I thought the book was a really good introduction to applied statistics and by using real life examples which most people would be able to relate to it makes a potentially dull subject interesting.
Reasonably early on the author points out that there’s a difference between making a prediction and making a forecast:
-
Prediction - a definitive and specific statement about when and where something will happen e.g. a major earthquake will hit Kyoto, Japan, on June 28.
-
Forecast - a probabilistic statement over a longer time scale e.g. there is a 60% chance of an earthquake in Southern California over the next 30 years. </ul> The book mainly focuses on the latter. </p>
We then move onto quite an interesting section about over fitting which is where we mistake noise for signal in our data.
I first came across this term when Jen and I were working through one of the Kaggle problems and were using a random forest of deliberately over fitted Decision Trees to do digit recognition.
It’s not a problem when we combine lots of decision trees together and use a majority wins algorithm to make our prediction but if we use just one of them its predictions on any new data will be completely wrong.
Later on in the book he points out that a lot of conspiracy theories come when we look at data retrospectively and can easily detect signal from noise in data when at the time it was much more difficult.
He also points out that sometimes there isn’t actually any signal, it’s all noise, and we can fall into the trap of looking for something that isn’t there. I think this 'noise' is what we’d refer to as random variation in the context of an A/B test.
Silver also encourages us to make sure that we understand the theory behind any inference we make:
Statistical inferences are much stronger when backed up by theory or at least some deeper thinking about their root causes.
When we were running A/B tests Sid encouraged people to think whether a theory about why conversion had changed made logical sense before assuming it was true which I think covers similar ground.
A big chunk of the book covers Bayes' theorem and how often when we’re making forecasts we have prior beliefs which it forces us to make explicit.
For example there is a section which talks about the probability a lady is being cheated on given that she’s found some underwear that she doesn’t recognise in her house.
In order to work out the probability she’s being cheated on we need to know the probability that she was being cheated on before she found the underwear. Silver suggests that since 4% of married partners cheat on their spouses that would be a good number to use.
He then goes on to show multiple other problems throughout the book that we can apply Bayes' theorem to.
Some other interesting things I picked up are that if we’re good at forecasting then being given more information should make our forecast better and that when we don’t have any special information we’re better off following the opinion of the crowd.
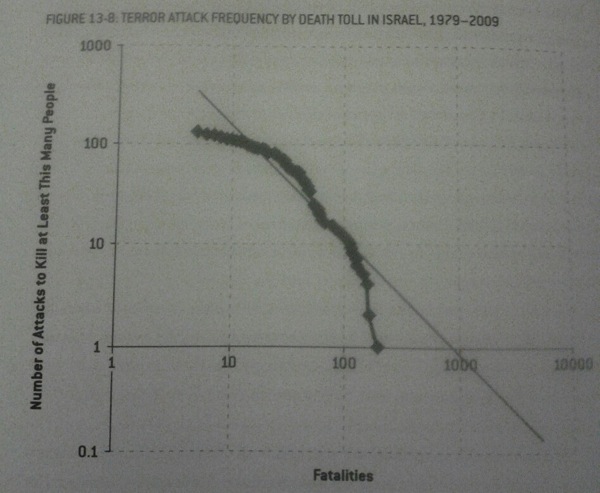
Silver also showed a clever trick for inferring data points on a data set which follows a power law i.e. the long tail distribution where there are very few massive events but lots of really small ones.
We have a power law distribution when modelling the number of terrorists attacks vs number of fatalities but if we change both scales to be logarithmic we can come up with a probability of how likely more deadly attacks are.
There is then some discussion of how we can make changes in the way that we treat terrorism to try and impact the shape of the chart e.g. in Israel Silver suggests that they really want to avoid a very deadly attack but at the expense of there being more smaller attacks.
A lot of the book is spent discussing weather/earthquake forecasting which is very interesting to read about but I couldn’t quite see a link back to the software context.
Overall though I found it an interesting read although there are probably a few places that you can skim over the detail and still get the gist of what he’s saying.
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.