
Polyglot Persistence: Embrace the ETL
Over the past few years I’ve seen the emergence of polyglot persistence i.e. using different data storage technologies for different data and in most situations we work that out up front.
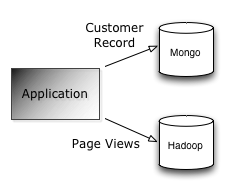
For example we might use MongoDB to store data about a customer journey through our website but we might simultaneously write page view data through to something like Hadoop or Redshift:
This works reasonably well but sometimes it might not be immediately obvious how we want to query our data when we first start collecting it and our storage choice might not be the best for writing these queries.
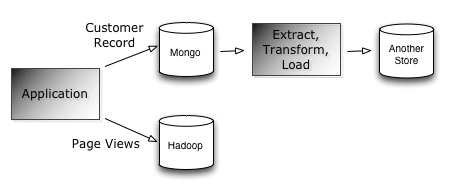
An interesting thing to think about at this stage is whether it makes sense to add a stage to our data processing pipeline where we write an ETL job to get it into a more appropriate format:
My initial experience doing this was when I created the ThoughtWorks graph which involved transforming data into a graph so that I could find links between people.
Ashok and I followed a similar approach for a client we went on to work for and it allowed us to find the answers to questions that couldn’t be answered when the data was in its original format.
The main down side to this approach is that we now have to keep two data sources in sync but it’s interesting to think about whether this trade off is worthwhile if it helps us gain new insights or find the answers to questions more quickly.
I don’t have any experience with how this approach plays out over time so I’d be interesting in hearing how people have got on with this approach/if it does or doesn’t work.
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.