
neo4j/cypher 2.0: The CASE statement
I’ve been playing around with how you might model Premier League managers tenures at different clubs in neo4j and eventually decided on the following model:
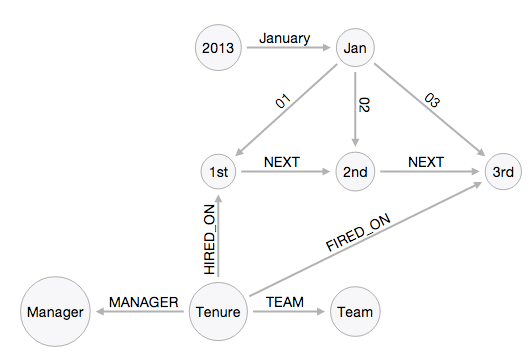
The date modelling is based on an approach I first came across in a shutl presentation and is described in more detail in the docs.
I created a dummy data set with some made up appointments and dismissals and then tried to write a query to show me who was the manager for a team on a specific date. ~cypher CREATE (year2013 { name: "2013" }) CREATE (january2013 { name: "January" }) CREATE (january012013 { name: "1st" }) CREATE (january022013 { name: "2nd" }) CREATE (january032013 { name: "3rd" }) CREATE (january042013 { name: "4th" }) CREATE (january052013 { name: "5th" }) CREATE (chelsea { name: "Chelsea", type: "team" }) CREATE (joseMourinho { name: "Jose Mourinho"}) CREATE (mourinhoChelsea { name: "Mourinho tenure at Chelsea" }) CREATE (manUtd { name: "Manchester United", type: "team" }) CREATE (davidMoyes { name: "David Moyes"}) CREATE (davidMoyesUnited { name: "Moyes tenure at Manchester United" }) CREATE (year2013)-[:`January`]-(january2013) CREATE (january2013)-[:`01`]-(january012013) CREATE (january2013)-[:`02`]-(january022013) CREATE (january2013)-[:`03`]-(january032013) CREATE (january2013)-[:`04`]-(january042013) CREATE (january2013)-[:`05`]-(january052013) CREATE (january012013)-[:NEXT]-(january022013) CREATE (january022013)-[:NEXT]-(january032013) CREATE (january032013)-[:NEXT]-(january042013) CREATE (january042013)-[:NEXT]-(january052013) CREATE (mourinhoChelsea)-[:HIRED_ON {date: "January 1st 2013"}]->(january012013) CREATE (mourinhoChelsea)-[:MANAGER]->(joseMourinho) CREATE (mourinhoChelsea)-[:TEAM]->(chelsea) CREATE (mourinhoChelsea)-[:FIRED_ON]->(january032013) CREATE (davidMoyesUnited)-[:HIRED_ON {date: "January 2nd 2013"}]->(january022013) CREATE (davidMoyesUnited)-[:MANAGER]->(davidMoyes) CREATE (davidMoyesUnited)-[:TEAM]->(manUtd) ~ ~cypher START team = node:node_auto_index('name:"Chelsea" name:"Manchester United"'), date = node:node_auto_index(name="5th") MATCH date<-[:NEXT*0..]-()<-[hire:HIRED_ON]-tenure-[:MANAGER]->manager, tenure-[:TEAM]->team, tenure-[fired?:FIRED_ON]-dateFired RETURN team.name, manager.name, hire.date, dateFired ~
The query starts from January 5th, then gets all the previous dates and looks for a 'HIRED_ON' relationship and then follows that to get the manager and the team for which it applies to.
We then traverse an optional 'FIRED_ON' relationship as well because we don’t want to say a manager is currently at a club if they’ve been fired.
It returns the following: ~text ==> ---------------------------------------------------------------------------------- ==> | team.name | manager.name | hire.date | dateFired | ==> ---------------------------------------------------------------------------------- ==> | "Manchester United" | "David Moyes" | "January 2nd 2013" |
In this data set Jose Mourinho gets fired on the 3rd January so Chelsea shouldn’t have a manager on the 5th January.
One way to exclude him is to collect all the dates that our 'NEXT' relationship takes us to and then check if the 'dateFired' is in that collection. If it is then the manager has been fired and we shouldn’t return them: ~cypher START team = node:node_auto_index('name:"Chelsea" name:"Manchester United"'), startDate = node:node_auto_index(name="5th") MATCH startDate<-[:NEXT*0..]-day WITH team, startDate, COLLECT(day) AS dates MATCH startDate<-[:NEXT*0..]-day<-[hire:HIRED_ON]-tenure-[:MANAGER]->manager, tenure-[:TEAM]->team, tenure-[?:FIRED_ON]-dateFired WHERE dateFired IS NULL OR NOT dateFired IN dates RETURN team.name, manager.name, hire.date, dateFired ~
That returns the following: ~text ==> ---------------------------------------------------------------------- ==> | team.name | manager.name | hire.date | dateFired | ==> ---------------------------------------------------------------------- ==> | "Manchester United" | "David Moyes" | "January 2nd 2013" |
Unfortunately we now don’t get a row for Chelsea because the WHERE clause filters Mourinho out.
I couldn’t think how to get around this so Wes suggested using neo4j 2.0 and the CASE statement which makes this very easy.
I eventually ended up with the following query which does the job: ~cypher START team = node:node_auto_index('name:"Chelsea" name:"Manchester United"'), startDate = node:node_auto_index(name="2nd") MATCH startDate<-[:NEXT*0..]-day WITH team, startDate, COLLECT(day) AS dates MATCH startDate<-[:NEXT*0..]-day<-[hire:HIRED_ON]-tenure-[:MANAGER]->manager, tenure-[:TEAM]->team, tenure-[?:FIRED_ON]->dateFired RETURN team.name, CASE WHEN dateFired is null THEN manager.name WHEN dateFired IN dates THEN null ELSE manager.name END as managerName, CASE WHEN dateFired is null THEN hire.date WHEN dateFired IN dates THEN null ELSE hire.date END as hireDate ~
Here we’ve introduced the CASE statement which works pretty similarly to how the SQL CASE statement works so it should be somehow familiar. That query returns the following: ~text ==> ---------------------------------------------------------- ==> | team.name | managerName | hireDate | ==> ---------------------------------------------------------- ==> | "Manchester United" | "David Moyes" | "January 2nd 2013" | ==> | "Chelsea" |
which is exactly what we want. Now I need to import a real data set to see what it looks like!
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.