
neo4j/cypher: Aggregating relationships within a path
I recently came across an interesting use case of paths in a graph where we wanted to calculate the frequency of communication between two people by showing how frequently each emailed the other.
The model looked like this:
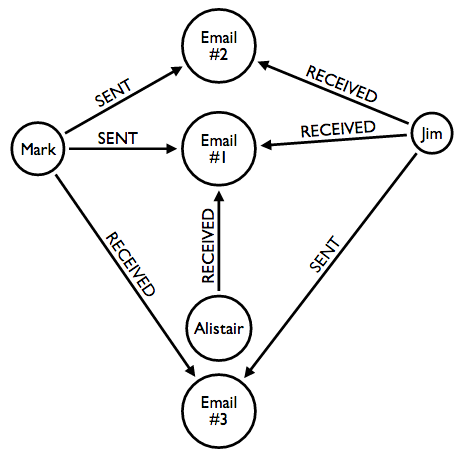
which we can create with the following cypher statements:
CREATE (email1 { name: 'Email 1', title: 'Some stuff' })
CREATE (email2 { name: 'Email 2', title: "Absolutely irrelevant" })
CREATE (email3 { name: 'Email 3', title: "Something else" })
CREATE (person1 { name: 'Mark' })
CREATE (person2 { name: 'Jim' })
CREATE (person3 { name: 'Alistair' })
CREATE (person1)-[:SENT]->(email1)
CREATE (person2)-[:RECEIVED]->(email1)
CREATE (person3)-[:RECEIVED]->(email1)
CREATE (person1)-[:SENT]->(email2)
CREATE (person2)-[:RECEIVED]->(email2)
CREATE (person2)-[:SENT]->(email3)
CREATE (person1)-[:RECEIVED]->(email3)We want to return a list containing pairs of people and how many times they emailed each other, so in this case we want to return a table showing the following:
+-------------------------------------------+
| Person 1 | Person 2 | P1 -> P2 | P2 -> P1 |
|-------------------------------------------|
| Alistair | Mark | 0 | 1 |
| Jim | Mark | 1 | 2 |
+-------------------------------------------+I started out with the following query which finds all the emails and then traverses out to find the sender and receiver and aggregates them together:
START email = node:node_auto_index('name:"Email 1" name:"Email 2" name: "Email 3"')
MATCH sender-[:SENT]->email<-[:RECEIVED]-receiver
RETURN sender.name, receiver.name, COUNT(email) AS countwhich returns the following:
==> +-------------------------------------+
==> | sender.name | receiver.name | count |
==> +-------------------------------------+
==> | "Mark" | "Jim" | 2 |
==> | "Jim" | "Mark" | 1 |
==> | "Mark" | "Alistair" | 1 |
==> +-------------------------------------+It gives us all the pairs that have sent emails to each other but doesn’t group them together which is a bit annoying.
Having realised that it was quite difficult to get that grouping of people if I started from the emails I changed the query to start from people instead and then traverse in on the emails they’d written to each other:
START personA = node:node_auto_index('name:"Mark" name:"Jim" name:"Alistair"'),
personB = node:node_auto_index('name:"Mark" name:"Jim" name:"Alistair"')
MATCH personA-[s:SENT]->email<-[r:RECEIVED]-personB
WHERE personA <> personB
WITH personA, personB, LENGTH(COLLECT(s)) AS AToB
MATCH personB-[s?:SENT]->email<-[r:RECEIVED]-personA
RETURN personA.name, personB.name, AToB, LENGTH(COLLECT(s)) AS BToAHere we start with our list of people and then find all the combinations where personA has sent an email that’s been received by personB.
If we execute just the first half of that we can see the email sent/received combinations:
START personA = node:node_auto_index('name:"Mark" name:"Jim" name:"Alistair"'),
personB = node:node_auto_index('name:"Mark" name:"Jim" name:"Alistair"')
MATCH personA-[s:SENT]->email<-[r:RECEIVED]-personB
WHERE personA <> personB
RETURN personA, personB, email==> +---------------------------------------------------------------------------------------------------------+
==> | personA | personB | email |
==> +---------------------------------------------------------------------------------------------------------+
==> | Node[4]{name:"Mark"} | Node[5]{name:"Jim"} | Node[1]{name:"Email 1",title:"Some stuff"} |
==> | Node[4]{name:"Mark"} | Node[5]{name:"Jim"} | Node[2]{name:"Email 2",title:"Absolutely irrelevant"} |
==> | Node[5]{name:"Jim"} | Node[4]{name:"Mark"} | Node[3]{name:"Email 3",title:"Something else"} |
==> | Node[4]{name:"Mark"} | Node[6]{name:"Alistair"} | Node[1]{name:"Email 1",title:"Some stuff"} |
==> +---------------------------------------------------------------------------------------------------------+In the second half of the query we find the inverse relationships but we also want to indicate if one person hasn’t sent any emails to the other one (e.g. Alistair to Mark) which is why I brought in the optional 'SENT' relationship. If we run that we get the following:
==> +-------------------------------------------+
==> | personA.name | personB.name | AToB | BToA |
==> +-------------------------------------------+
==> | "Jim" | "Mark" | 1 | 2 |
==> | "Mark" | "Alistair" | 1 | 0 |
==> | "Mark" | "Jim" | 2 | 1 |
==> +-------------------------------------------+It’s a bit better in that we’ve now got the emails sent by pairs of people on the same row but we still have duplication e.g. Jim/Mark and Mark/Jim show as separate rows even though they show the same information.
We also won’t see a row if Person A hasn’t sent an email to PersonB even if Person B has emailed Person A.
At this stage I was a bit stuck but Max pointed out that we could use the all shortest paths algorithm to solve the problem.
We started out with the following query:
START personA = node:node_auto_index('name:"Mark" name:"Jim" name:"Alistair"'),
personB = node:node_auto_index('name:"Mark" name: "Jim" name: "Alistair"')
WITH personA,personB
MATCH p = AllShortestPaths(personA-[:SENT|RECEIVED*..2]-personB)
RETURN pwhich returns:
==> +------------------------------------------------------------------------------------------------------------------------------+
==> | p |
==> +------------------------------------------------------------------------------------------------------------------------------+
==> | [Node[4]{name:"Mark"}] |
==> | [Node[4]{name:"Mark"},:SENT[0] {},Node[1]{name:"Email 1",title:"Some stuff"},:RECEIVED[1] {},Node[5]{name:"Jim"}] |
==> | [Node[4]{name:"Mark"},:SENT[3] {},Node[2]{name:"Email 2",title:"Absolutely irrelevant"},:RECEIVED[4] {},Node[5]{name:"Jim"}] |
==> | [Node[4]{name:"Mark"},:RECEIVED[6] {},Node[3]{name:"Email 3",title:"Something else"},:SENT[5] {},Node[5]{name:"Jim"}] |
==> | [Node[4]{name:"Mark"},:SENT[0] {},Node[1]{name:"Email 1",title:"Some stuff"},:RECEIVED[2] {},Node[6]{name:"Alistair"}] |
==> | [Node[5]{name:"Jim"},:RECEIVED[1] {},Node[1]{name:"Email 1",title:"Some stuff"},:SENT[0] {},Node[4]{name:"Mark"}] |
==> | [Node[5]{name:"Jim"},:RECEIVED[4] {},Node[2]{name:"Email 2",title:"Absolutely irrelevant"},:SENT[3] {},Node[4]{name:"Mark"}] |
==> | [Node[5]{name:"Jim"},:SENT[5] {},Node[3]{name:"Email 3",title:"Something else"},:RECEIVED[6] {},Node[4]{name:"Mark"}] |
==> | [Node[5]{name:"Jim"}] |
==> | [Node[5]{name:"Jim"},:RECEIVED[1] {},Node[1]{name:"Email 1",title:"Some stuff"},:RECEIVED[2] {},Node[6]{name:"Alistair"}] |
==> | [Node[6]{name:"Alistair"},:RECEIVED[2] {},Node[1]{name:"Email 1",title:"Some stuff"},:SENT[0] {},Node[4]{name:"Mark"}] |
==> | [Node[6]{name:"Alistair"},:RECEIVED[2] {},Node[1]{name:"Email 1",title:"Some stuff"},:RECEIVED[1] {},Node[5]{name:"Jim"}] |
==> | [Node[6]{name:"Alistair"}] |
==> +------------------------------------------------------------------------------------------------------------------------------+Since we’re only really interested in the emails that people have sent to each other we’ll narrow down the result set to only include those paths:
START personA = node:node_auto_index('name:"Mark" name:"Jim" name:"Alistair"'),
personB = node:node_auto_index('name:"Mark" name: "Jim" name: "Alistair"')
WITH personA,personB
MATCH p = AllShortestPaths(personA-[:SENT|RECEIVED*..2]-personB)
WHERE ANY (x IN relationships(p) WHERE TYPE(x)= 'SENT')
RETURN p==> +------------------------------------------------------------------------------------------------------------------------------+
==> | p |
==> +------------------------------------------------------------------------------------------------------------------------------+
==> | [Node[4]{name:"Mark"},:SENT[0] {},Node[1]{name:"Email 1",title:"Some stuff"},:RECEIVED[1] {},Node[5]{name:"Jim"}] |
==> | [Node[4]{name:"Mark"},:SENT[3] {},Node[2]{name:"Email 2",title:"Absolutely irrelevant"},:RECEIVED[4] {},Node[5]{name:"Jim"}] |
==> | [Node[4]{name:"Mark"},:RECEIVED[6] {},Node[3]{name:"Email 3",title:"Something else"},:SENT[5] {},Node[5]{name:"Jim"}] |
==> | [Node[4]{name:"Mark"},:SENT[0] {},Node[1]{name:"Email 1",title:"Some stuff"},:RECEIVED[2] {},Node[6]{name:"Alistair"}] |
==> | [Node[5]{name:"Jim"},:RECEIVED[1] {},Node[1]{name:"Email 1",title:"Some stuff"},:SENT[0] {},Node[4]{name:"Mark"}] |
==> | [Node[5]{name:"Jim"},:RECEIVED[4] {},Node[2]{name:"Email 2",title:"Absolutely irrelevant"},:SENT[3] {},Node[4]{name:"Mark"}] |
==> | [Node[5]{name:"Jim"},:SENT[5] {},Node[3]{name:"Email 3",title:"Something else"},:RECEIVED[6] {},Node[4]{name:"Mark"}] |
==> | [Node[6]{name:"Alistair"},:RECEIVED[2] {},Node[1]{name:"Email 1",title:"Some stuff"},:SENT[0] {},Node[4]{name:"Mark"}] |
==> +------------------------------------------------------------------------------------------------------------------------------+There’s currently some duplication because we have paths going both ways between people included. e.g.
[Node[4]{name:"Mark"},:SENT[0] {},Node[1]{name:"Email 1",title:"Some stuff"},:RECEIVED[1] {},Node[5]{name:"Jim"}]and:
[Node[5]{name:"Jim"},:RECEIVED[1] {},Node[1]{name:"Email 1",title:"Some stuff"},:SENT[0] {},Node[4]{name:"Mark"}]refer to the same thing.
We’ll filter by keeping the starting node which has a higher node id - we could use any property to do this comparison but id will do:
START personA = node:node_auto_index('name:"Mark" name:"Jim" name:"Alistair"'),
personB = node:node_auto_index('name:"Mark" name: "Jim" name: "Alistair"')
WITH personA,personB
MATCH p = AllShortestPaths(personA-[:SENT|RECEIVED*..2]-personB)
WHERE ANY (x IN relationships(p) WHERE TYPE(x)= 'SENT')
AND ID(head(nodes(p))) > ID(head((tail(tail(nodes(p))))))
RETURN p==> +------------------------------------------------------------------------------------------------------------------------------+
==> | p |
==> +------------------------------------------------------------------------------------------------------------------------------+
==> | [Node[5]{name:"Jim"},:RECEIVED[1] {},Node[1]{name:"Email 1",title:"Some stuff"},:SENT[0] {},Node[4]{name:"Mark"}] |
==> | [Node[5]{name:"Jim"},:RECEIVED[4] {},Node[2]{name:"Email 2",title:"Absolutely irrelevant"},:SENT[3] {},Node[4]{name:"Mark"}] |
==> | [Node[5]{name:"Jim"},:SENT[5] {},Node[3]{name:"Email 3",title:"Something else"},:RECEIVED[6] {},Node[4]{name:"Mark"}] |
==> | [Node[6]{name:"Alistair"},:RECEIVED[2] {},Node[1]{name:"Email 1",title:"Some stuff"},:SENT[0] {},Node[4]{name:"Mark"}] |
==> +------------------------------------------------------------------------------------------------------------------------------+Now we just need to do a bit more manipulation of these paths and we have exactly what we need:
START personA = node:node_auto_index('name:"Mark" name:"Jim" name:"Alistair"'),
personB = node:node_auto_index('name:"Mark" name: "Jim" name: "Alistair"')
WITH personA,personB
MATCH p = AllShortestPaths(personA-[:SENT|RECEIVED*..2]-personB)
WHERE ANY (x IN relationships(p) WHERE TYPE(x)= 'SENT')
AND ID(head(nodes(p))) > ID(head((tail(tail(nodes(p))))))
RETURN HEAD(NODES(p)) AS personA,
HEAD((TAIL(TAIL(NODES(p))))) AS personB,
LENGTH(FILTER(y IN COLLECT(HEAD(RELS(p))): TYPE(y)= 'SENT')) as AToB,
LENGTH(FILTER(y IN COLLECT(HEAD(TAIL(RELS(p)))): TYPE(y)= 'SENT')) as BToAWhat we’ve done here is count the number of 'SENT' relationships from person A’s side of the path and then do the same for person B’s side of the path.
There’s currently no way to do slicing of a collection in cypher otherwise we wouldn’t need those nested calls to TAIL!
We do however get the result we want:
==> +---------------------------------------------------------------+
==> | personA | personB | AToB | BToA |
==> +---------------------------------------------------------------+
==> | Node[6]{name:"Alistair"} | Node[4]{name:"Mark"} | 0 | 1 |
==> | Node[5]{name:"Jim"} | Node[4]{name:"Mark"} | 1 | 2 |
==> +---------------------------------------------------------------+I have no idea how well this query would perform for any significantly sized data set but it’s an interesting query nonetheless.
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.