
Topic Modelling: Working out the optimal number of topics
In my continued exploration of topic modelling I came across The Programming Historian blog and a post showing how to derive topics from a corpus using the Java library mallet.
The instructions on the blog make it very easy to get up and running but as with other libraries I’ve used, you have to specify how many topics the corpus consists of. I’m never sure what value to select but the authors make the following suggestion:
How do you know the number of topics to search for? Is there a natural number of topics? What we have found is that one has to run the train-topics with varying numbers of topics to see how the composition file breaks down. If we end up with the majority of our original texts all in a very limited number of topics, then we take that as a signal that we need to increase the number of topics; the settings were too coarse. There are computational ways of searching for this, including using MALLETs hlda command, but for the reader of this tutorial, it is probably just quicker to cycle through a number of iterations (but for more see Griffiths, T. L., & Steyvers, M. (2004). Finding scientific topics. Proceedings of the National Academy of Science, 101, 5228-5235).
Since I haven’t yet had the time to dive into the paper or explore how to use the appropriate option in mallet I thought I’d do some variations on the stop words and number of topics and see how that panned out.
As I understand it, the idea is to try and get a uniform spread of topics -> documents i.e. we don’t want all the documents to have the same topic otherwise any topic similarity calculations we run won’t be that interesting. </p>
I tried running mallet with 10,15,20 and 30 topics and also varied the stop words used. I had one version which just stripped out the main characters and the word 'narrator' & another where I stripped out the top 20% of words by occurrence and any words that appeared less than 10 times.
The reason for doing this was that it should identify interesting phrases across episodes better than TF/IDF can while not just selecting the most popular words across the whole corpus.
I used mallet from the command line and ran it in two parts.
-
Generate the model
-
Work out the allocation of topics and documents based on hyper parameters
I wrote a script to help me out:
#!/bin/sh
train_model() {
./mallet-2.0.7/bin/mallet import-dir \
--input mallet-2.0.7/sample-data/himym \
--output ${2} \
--keep-sequence \
--remove-stopwords \
--extra-stopwords ${1}
}
extract_topics() {
./mallet-2.0.7/bin/mallet train-topics \
--input ${2} --num-topics ${1} \
--optimize-interval 20 \
--output-state himym-topic-state.gz \
--output-topic-keys output/himym_${1}_${3}_keys.txt \
--output-doc-topics output/himym_${1}_${3}_composition.txt
}
train_model "stop_words.txt" "output/himym.mallet"
train_model "main-words-stop.txt" "output/himym.main.words.stop.mallet"
extract_topics 10 "output/himym.mallet" "all.stop.words"
extract_topics 15 "output/himym.mallet" "all.stop.words"
extract_topics 20 "output/himym.mallet" "all.stop.words"
extract_topics 30 "output/himym.mallet" "all.stop.words"
extract_topics 10 "output/himym.main.words.stop.mallet" "main.stop.words"
extract_topics 15 "output/himym.main.words.stop.mallet" "main.stop.words"
extract_topics 20 "output/himym.main.words.stop.mallet" "main.stop.words"
extract_topics 30 "output/himym.main.words.stop.mallet" "main.stop.words"As you can see, this script first generates a bunch of models from text files in 'mallet-2.0.7/sample-data/himym' - there is one file per episode of HIMYM. We then use that model to generate differently sized topic models.
The output is two files; one containing a list of topics and another describing what percentage of the words in each document come from each topic.
$ cat output/himym_10_all.stop.words_keys.txt
0 0.08929 back brad natalie loretta monkey show call classroom mitch put brunch betty give shelly tyler interview cigarette mc laren
1 0.05256 zoey jerry arthur back randy arcadian gael simon blauman blitz call boats becky appartment amy gary made steve boat
2 0.06338 back claudia trudy doug int abby call carl stuart voix rachel stacy jenkins cindy vo katie waitress holly front
3 0.06792 tony wendy royce back jersey jed waitress bluntly lucy made subtitle film curt mosley put laura baggage officer bell
4 0.21609 back give patrice put find show made bilson nick call sam shannon appartment fire robots top basketball wrestlers jinx
5 0.07385 blah bob back thanksgiving ericksen maggie judy pj valentine amanda made call mickey marcus give put dishes juice int
6 0.04638 druthers karen back jen punchy jeanette lewis show jim give pr dah made cougar call jessica sparkles find glitter
7 0.05751 nora mike pete scooter back magazine tiffany cootes garrison kevin halloween henrietta pumpkin slutty made call bottles gruber give
8 0.07321 ranjit back sandy mary burger call find mall moby heather give goat truck made put duck found stangel penelope
9 0.31692 back give call made find put move found quinn part ten original side ellen chicago italy locket mine show$ head -n 10 output/himym_10_all.stop.words_composition.txt
#doc name topic proportion ...
0 file:/Users/markneedham/projects/mallet/mallet-2.0.7/sample-data/himym/1.txt 0 0.70961794636687 9 0.1294699168584466 8 0.07950442338871108 2 0.07192178481473664 4 0.008360809510263838 5 2.7862560133367015E-4 3 2.562409242784946E-4 7 2.1697378721335337E-4 1 1.982849604752168E-4 6 1.749937876710496E-4
1 file:/Users/markneedham/projects/mallet/mallet-2.0.7/sample-data/himym/10.txt 2 0.9811551470820473 9 0.016716882136209997 4 6.794128563082893E-4 0 2.807350575301132E-4 5 2.3219634098530471E-4 8 2.3018997315244256E-4 3 2.1354177341696056E-4 7 1.8081798384467614E-4 1 1.6524340216541808E-4 6 1.4583339433951297E-4
2 file:/Users/markneedham/projects/mallet/mallet-2.0.7/sample-data/himym/100.txt 2 0.724061485807234 4 0.13624729774423758 0 0.13546964196228636 9 0.0019436342339785994 5 4.5291919356563914E-4 8 4.490055982996677E-4 3 4.1653183421485213E-4 7 3.5270123154213927E-4 1 3.2232165301666123E-4 6 2.8446074162457316E-4
3 file:/Users/markneedham/projects/mallet/mallet-2.0.7/sample-data/himym/101.txt 2 0.7815231689893246 0 0.14798271520316794 9 0.023582384458063092 8 0.022251052243582908 1 0.022138209217973336 4 0.0011804626661380394 5 4.0343527385745457E-4 3 3.7102343418895774E-4 7 3.1416667687862693E-4 6 2.533818368250992E-
4 file:/Users/markneedham/projects/mallet/mallet-2.0.7/sample-data/himym/102.txt 6 0.6448245189567259 4 0.18612146979166502 3 0.16624873439661025 9 0.0012233726722317548 0 3.4467218590717303E-4 5 2.850788252495599E-4 8 2.8261550915084904E-4 2 2.446611421432842E-4 7 2.2199909869250053E-4 1 2.028774216237081E-
5 file:/Users/markneedham/projects/mallet/mallet-2.0.7/sample-data/himym/103.txt 8 0.7531586740033047 5 0.17839539108961253 0 0.06512376460651902 9 0.001282794040111701 4 8.746645156304241E-4 3 2.749100345664577E-4 2 2.5654476523149865E-4 7 2.327819863700214E-4 1 2.1273153572848481E-4 6 1.8774342292520802E-4
6 file:/Users/markneedham/projects/mallet/mallet-2.0.7/sample-data/himym/104.txt 7 0.9489502365148181 8 0.030091466847852504 4 0.017936457663121977 9 0.0013482824985091328 0 3.7986419553884905E-4 5 3.141861834124008E-4 3 2.889445824352445E-4 2 2.6964174000656E-4 1 2.2359178288566958E-4 6 1.9732799141958482E-4
7 file:/Users/markneedham/projects/mallet/mallet-2.0.7/sample-data/himym/105.txt 8 0.7339694064061175 7 0.1237041841318045 9 0.11889696041555338 0 0.02005288536233353 4 0.0014026751618923005 5 4.793786828705149E-4 3 4.408655780020889E-4 2 4.1141370625324785E-4 1 3.411516484151411E-4 6 3.0107890675777946E-4
8 file:/Users/markneedham/projects/mallet/mallet-2.0.7/sample-data/himym/106.txt 5 0.37064909999661005 9 0.3613559917055785 0 0.14857567731040344 6 0.09545466082502917 4 0.022300625744661403 8 3.8725629469313333E-4 3 3.592484711785775E-4 2 3.3524900189121E-4 7 3.041961449432886E-4 1 2.779945050112539E-4The output is a bit tricky to understand on its own so I did a bit of post processing using pandas and then ran the results of that through matplotlib to see the distribution of documents for different topics sizes with different stop words. You can see the script here.
I ended up with the following chart:
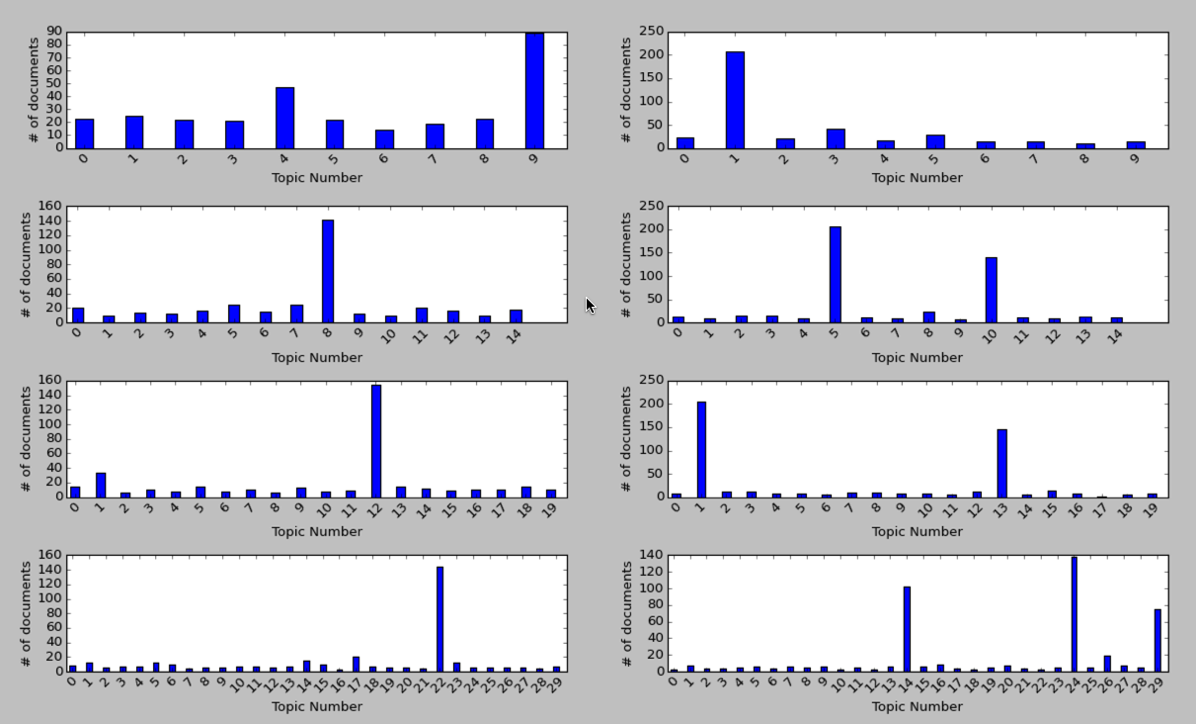
On the left hand side we’re using more stop words and on the right just the main ones. For most of the variations there are one or two topics which most documents belong to but interestingly the most uniform distribution seems to be when we have few topics.
These are the main words for the most popular topics on the left hand side:
15 topics
8 0.50732 back give call made put find found part move show side ten mine top abby front fire full fianc20 topics
12 0.61545 back give call made put find show found part move side mine top front ten full cry fire fianc30 topics
22 0.713 back call give made put find show part found side move front ten full top mine fire cry bottom~~~
<p>All contain more or less the same words which at first glance seem like quite generic words so I'm surprised they weren't excluded.</p>
<p>On the right hand side we haven't removed many words so we'd expect common words in the English language to dominate. Let's see if they do:</p>
<em>10 topics</em>
~~~text
1 3.79451 don yeah ll hey ve back time guys good gonna love god night wait uh thing guy great make15 topics
5 2.81543 good time love ll great man guy ve night make girl day back wait god life yeah years thing
10 1.52295 don yeah hey gonna uh guys didn back ve ll um kids give wow doesn thing totally god fine20 topics
1 3.06732 good time love wait great man make day back ve god life years thought big give apartment people work
13 1.68795 don yeah hey gonna ll uh guys night didn back ve girl um kids wow guy kind thing baby30 topics
14 1.42509 don yeah hey gonna uh guys didn back ve um thing ll kids wow time doesn totally kind wasn
24 2.19053 guy love man girl wait god ll back great yeah day call night people guys years home room phone
29 1.84685 good make ve ll stop time made nice put feel love friends big long talk baby thought things happyAgain we have similar words across each run and as expected they are all quite generic words.
My take away from this exploration is that I should vary the stop word percentages as well and see if that leads to an improved distribution.
Taking out very common words like we do with the left hand side charts seems to make sense although I need to work out why there’s a single outlier in each group.
The authors suggest that having the majority of our texts in a small number of topics means we need to create more of them so I will investigate that too.
The code is all on github along with the transcripts so give it a try and let me know what you think.
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.