
Neo4j: Facts as nodes
On Tuesday I spoke at the Neo4j London user group about incrementally building a recommendation engine and described the 'facts as nodes' modeling pattern, defined as follows in the Graph Databases book:
When two or more domain entities interact for a period of time, a fact emerges. We represent a fact as a separate node with connections to each of the entities engaged in that fact. Modeling an action in terms of its product—that is, in terms of the thing that results from the action—produces a similar structure: an intermediate node that represents the outcome of an interaction between two or more entities.
We started with the following model describing a meetup member and the groups they’ve joined:

This model works well for the query it was defined for - find groups similar to ones that I’m already a member of:
MATCH (member:Member {name: "Mark Needham"})-[:MEMBER_OF]->(group)-[:HAS_TOPIC]->(topic)
WITH member, topic, COUNT(*) AS score
MATCH (topic)<-[:HAS_TOPIC]-(otherGroup)
WHERE NOT (member)-[:MEMBER_OF]->(otherGroup)
RETURN otherGroup.name, COLLECT(topic.name), SUM(score) as score
ORDER BY score DESCPrefixing that query with the 'PROFILE' keyword yields a query plan and the following summary text:
Cypher version: CYPHER 2.3, planner: COST. 89100 total db hits in 113 ms.In this model it feels like there is a membership fact waiting to become a node.
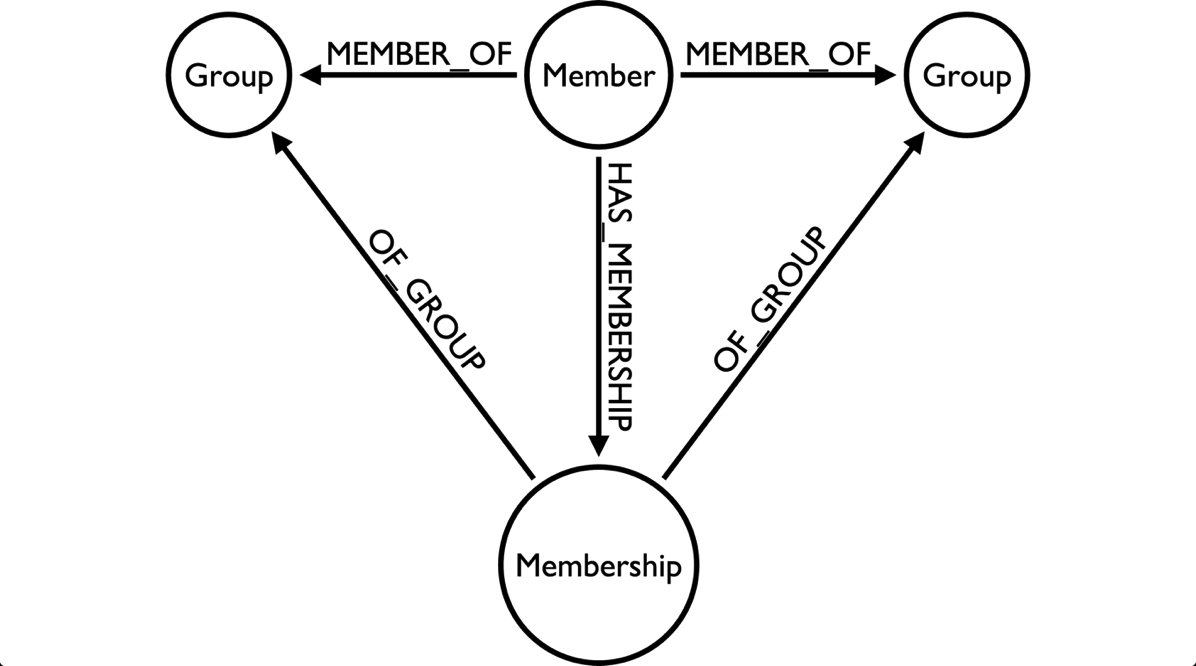
We can refactor towards that model with the following query:
MATCH (member:Member)-[rel:MEMBER_OF]->(group)
MERGE (membership:Membership {id: member.id + "_" + group.id})
SET membership.joined = rel.joined
MERGE (member)-[:HAS_MEMBERSHIP]->(membership)
MERGE (membership)-[:OF_GROUP]->(group);We’d answer our initial question with the following query:
MATCH (member:Member {name: "Mark Needham"})-[:HAS_MEMBERSHIP]->()-[:OF_GROUP]->(group:Group)-[:HAS_TOPIC]->(topic)
WITH member, topic, COUNT(*) AS score
MATCH (topic)<-[:HAS_TOPIC]-(otherGroup)
WHERE NOT (member)-[:HAS_MEMBERSHIP]->(:Membership)-[:OF_GROUP]->(otherGroup:Group)
RETURN otherGroup.name, COLLECT(topic.name), SUM(score) as score
ORDER BY score DESCat the following cost:
Cypher version: CYPHER 2.3, planner: COST. 468201 total db hits in 346 ms.The membership node hasn’t proved its value yet - it does 4x more work to get the same result. However, the next question we want to answer is 'what group do people join after the Neo4j user group?' where it might come in handy.
First we’ll add a 'NEXT' relationship between a user’s adjacent group memberships by writing the following query:
MATCH (member:Member)-[:HAS_MEMBERSHIP]->(membership)
WITH member, membership ORDER BY member.id, membership.joined
WITH member, COLLECT(membership) AS memberships
UNWIND RANGE(0,SIZE(memberships) - 2) as idx
WITH memberships[idx] AS m1, memberships[idx+1] AS m2
MERGE (m1)-[:NEXT]->(m2);And now for the query:
MATCH (group:Group {name: "Neo4j - London User Group"})<-[:OF_GROUP]-(membership)-[:NEXT]->(nextMembership),
(membership)<-[:HAS_MEMBERSHIP]-(member:Member)-[:HAS_MEMBERSHIP]->(nextMembership),
(nextMembership)-[:OF_GROUP]->(nextGroup)
RETURN nextGroup.name, COUNT(*) AS times
ORDER BY times DESCCypher version: CYPHER 2.3, planner: COST. 23671 total db hits in 39 ms.And for comparison - the same query using the initial model:
MATCH (group:Group {name: "Neo4j - London User Group"})<-[membership:MEMBER_OF]-(member),
(member)-[otherMembership:MEMBER_OF]->(otherGroup)
WHERE membership.joined < otherMembership.joined
WITH member, otherGroup
ORDER BY otherMembership.joined
WITH member, COLLECT(otherGroup)[0] AS nextGroup
RETURN nextGroup.name, COUNT(*) AS times
ORDER BY times DESCCypher version: CYPHER 2.3, planner: COST. 86179 total db hits in 138 ms.This time the membership model does 3x less work, so depending on the question a different model works better.
Given this observation we might choose to keep both models. The disadvantage of doing that is that we pay write and maintenance penalties to keep them both in sync. e.g. this is what queries to add a new membership or remove one would look like
Adding group membership
WITH "Mark Needham" AS memberName,
"Neo4j - London User Group" AS groupName,
timestamp() AS now
MATCH (group:Group {name: groupName})
MATCH (member:Member {name: memberName})
MERGE (member)-[memberOfRel:MEMBER_OF]->(group)
ON CREATE SET memberOfRel.time = now
MERGE (membership:Membership {id: member.id + "_" + group.id})
ON CREATE SET membership.joined = now
MERGE (member)-[:HAS_MEMBERSHIP]->(membership)
MERGE (membership)-[:OF_GROUP]->(group)Removing group membership
WITH "Mark Needham" AS memberName,
"Neo4j - London User Group" AS groupName,
timestamp() AS now
MATCH (group:Group {name: groupName})
MATCH (member:Member {name: memberName})
MATCH (member)-[memberOfRel:MEMBER_OF]->(group)
MATCH (membership:Membership {id: member.id + "_" + group.id})
MATCH (member)-[hasMembershipRel:HAS_MEMBERSHIP]->(membership)
MATCH (membership)-[ofGroupRel:OF_GROUP]->(group)
DELETE memberOfRel, hasMembershipRel, ofGroupRelThe dataset is on github so take a look at it and send any questions my way.
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.