
Clojure: Reading and writing a reasonably sized file
In a post a couple of days ago I described some code I’d written in R to find out all the features with zero variance in the Kaggle Digit Recognizer data set and yesterday I started working on some code to remove those features.
Jen and I had previously written some code to parse the training data in Clojure so I thought I’d try and adapt that to write out a new file without the unwanted pixels.
In the first version we’d encapsulated the reading of the file and parsing of it into a more useful data structure like so:
(defn get-pixels [pix] (map #( Integer/parseInt %) pix))
(defn create-tuple [[ head & rem]] {:pixels (get-pixels rem) :label head})
(defn tuples [rows] (map create-tuple rows))
(defn parse-row [row] (map #(clojure.string/split % #",") row))
(defn read-raw [path n]
(with-open [reader (clojure.java.io/reader path)] (vec (take n (rest (line-seq reader))))))
(def read-train-set-raw (partial read-raw "data/train.csv"))
(def parsed-rows (tuples (parse-row (read-train-set-raw 42000))))So the def parsed-rows gives an in memory representation of a row where we’ve separated the label and pixels into different key entries in a map.
We wanted to remove any pixels which had a variance of 0 across the data set which in this case means that they always have a value of 0:
(def dead-to-us-pixels
[0 1 2 3 4 5 6 7 8 9 10 11 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 52 53 54 55 56 57 82 83 84 85 111 112 139 140 141 168 196 392 420 421 448 476 532 560 644 645 671 672 673 699 700 701 727 728 729 730 731 754 755 756 757 758 759 760 780 781 782 783])
(defn in?
"true if seq contains elm"
[seq elm]
(some #(= elm %) seq))
(defn dead-to-us? [pixel-with-index]
(in? dead-to-us-pixels (first pixel-with-index)))
(defn remove-unwanted-pixels [row]
(let [new-pixels
(->> row :pixels (map-indexed vector) (remove dead-to-us?) (map second))]
{:pixels new-pixels :label (:label row)}))
(defn -main []
(with-open [wrt (clojure.java.io/writer "/tmp/attempt-1.txt")]
(doseq [line parsed-rows]
(let [line-without-pixels (to-file-format (remove-unwanted-pixels line))]
(.write wrt (str line-without-pixels "\n"))))))We then ran the main method using 'leon run' which wrote out the new file.
A print screen of the heap space usage while this function was running looks like this:
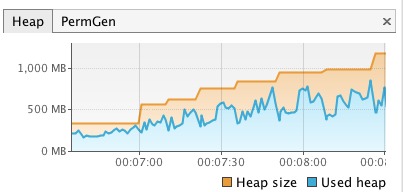
While I was writing this version of the function I made a mistake somewhere and ended up passing the wrong data structure to one of the functions which resulted in all the intermediate steps that the data structure goes through getting stored in memory and caused an OutOfMemory exception.
A heap dump showed the following:

When I reduced the size of the erroneous collection by using a 'take 10' I got an exception indicating that the function couldn’t process the data structure which allowed me to sort it out.
I initially thought that the problem was to do with the loading of the file into memory at all but since the above seems to work I don’t think it is.
When I was working along that theory Jen suggested it might make more sense to do the reading and writing of the files within a 'with-open' which tallies with a suggestion I came across in a StackOverflow post.
I ended up with the following code:
(defn split-on-comma [line]
(string/split line #","))
(defn clean-train-file []
(with-open [rdr (clojure.java.io/reader "data/train.csv")
wrt (clojure.java.io/writer "/tmp/attempt-2.csv")]
(doseq [line (drop 1 (line-seq rdr))]
(let [line-with-removed-pixels
((comp to-file-format remove-unwanted-pixels create-tuple split-on-comma) line)]
(.write wrt (str line-with-removed-pixels "\n"))))))Which got called in the main method like this:
(defn -main [] (clean-train-file))This version had the following heap usage:
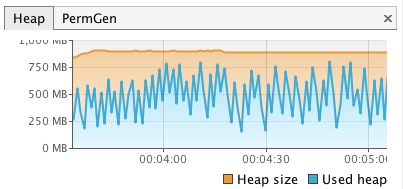
Its peaks are slightly lower than the first one and it seems like it buffers a bunch of lines, writes them out to the file (and therefore out of memory) and repeats.
Any thoughts on this approach are as always very welcome!
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.