
Apache Pinot: Sorted indexes on real-time tables
I’ve recently been learning all about Apache Pinot’s sorted forward indexes, and in my first blog post I explained how they work for offline tables. In this blog post we’ll learn how sorted indexes work with real-time tables.

Launch Components
We’re going to spin up a local instance of Pinot and Kafka using the following Docker compose config:
version: '3.7'
services:
zookeeper:
image: zookeeper:3.5.6
hostname: zookeeper
container_name: zookeeper-strava-realtime
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
kafka:
image: wurstmeister/kafka:latest
restart: unless-stopped
container_name: "kafka-strava"
ports:
- "9092:9092"
expose:
- "9093"
depends_on:
- zookeeper
environment:
KAFKA_ZOOKEEPER_CONNECT: zookeeper-strava-realtime:2181/kafka
KAFKA_BROKER_ID: 0
KAFKA_ADVERTISED_HOST_NAME: kafka-strava
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka-strava:9093,OUTSIDE://localhost:9092
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9093,OUTSIDE://0.0.0.0:9092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,OUTSIDE:PLAINTEXT
pinot-controller:
image: apachepinot/pinot:0.9.3
command: "StartController -zkAddress zookeeper-strava-realtime:2181 -dataDir /data"
container_name: "pinot-controller-strava-realtime"
volumes:
- ./config:/config
- ./data-realtime:/data
restart: unless-stopped
ports:
- "9000:9000"
depends_on:
- zookeeper
pinot-broker:
image: apachepinot/pinot:0.9.3
command: "StartBroker -zkAddress zookeeper-strava-realtime:2181"
restart: unless-stopped
container_name: "pinot-broker-strava-realtime"
ports:
- "8099:8099"
depends_on:
- pinot-controller
pinot-server:
image: apachepinot/pinot:0.9.3
command: "StartServer -zkAddress zookeeper-strava-realtime:2181"
restart: unless-stopped
container_name: "pinot-server-strava-realtime"
depends_on:
- pinot-brokerWe can launch all the components by running the following command:
docker-compose upCreate Schema
We’re going to explore sorted indexes using a dataset of my Strava activities, the same one that we used in the first blog post. The schema is described below:
{
"schemaName": "activities",
"dimensionFieldSpecs": [
{
"name": "id",
"dataType": "LONG"
},
{
"name": "altitude",
"dataType": "DOUBLE"
},
{
"name": "hr",
"dataType": "INT"
},
{
"name": "cadence",
"dataType": "INT"
},
{
"name": "rawTime",
"dataType": "INT"
},
{
"name": "distance",
"dataType": "DOUBLE"
},
{
"name": "lat",
"dataType": "DOUBLE"
},
{
"name": "lon",
"dataType": "DOUBLE"
},
{
"name": "location",
"dataType": "BYTES"
}
],
"dateTimeFieldSpecs": [{
"name": "timestamp",
"dataType": "TIMESTAMP",
"format" : "1:MILLISECONDS:EPOCH",
"granularity": "1:MILLISECONDS"
}]
}We can create the schema by running the following command:
docker exec -it pinot-controller-strava-realtime bin/pinot-admin.sh AddSchema \
-schemaFile /config/schema.json -execWhat is a sorted index?
Before we ingest any data, let’s remind ourselves about the definition of a sorted index.
When a column is physically sorted, Pinot uses a sorted forward index with run-length encoding on top of the dictionary-encoding. Instead of saving dictionary ids for each document id, Pinot will store a pair of start and end document ids for each value.
docs.pinot.apache.org/basics/indexing/forward-index#sorted-forward-index-with-run-length-encoding
A diagram showing how a sorted index works conceptually is shown below:
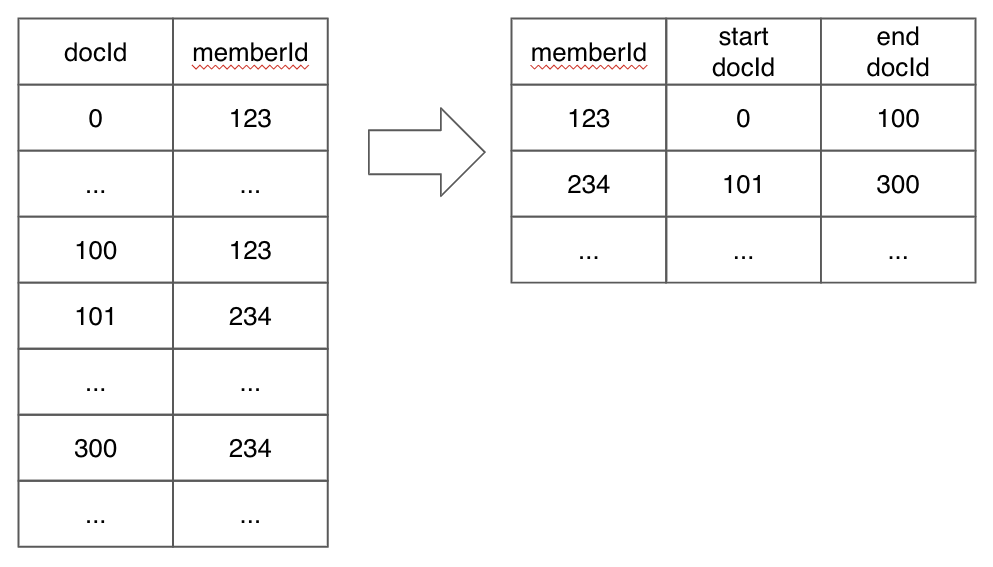
The advantage of having a sorted index is that queries that filter by that column will be more performant since the query engine doesn’t need to scan through every document to check if they match the filtering criteria.
For real-time tables we can specify a sorted index in the tableIndexConfig:
{
"tableIndexConfig": {
"sortedColumn": [
"column_name"
],
}
}When Pinot commits the segment it will ensure that the data is sorted based on this sorted column. It will then do a single pass over every other column to check whether the data in those columns is sorted. Columns that contain sorted data will also use a sorted forward index. This means that it’s possible that multiple columns will use a sorted index even though one column is guaranteed to use a sorted index.
|
Note
|
Sorted indexes are determined for each segment. This means that a column could be sorted in one segment, but not in another one. |
Data Ingestion into Kafka
Now let’s ingest some data into a Kafka topic.
First let’s install the Confluent Kafka client:
pip install confluent-kafkaAnd now we’ll import some documents into the activities-realtime topic.
Import the following libraries:
import json
from confluent_kafka import ProducerDefine an acknowledge function and configure our Kafka producer:
def acked(err, msg):
if err is not None:
print("Failed to deliver message: {0}: {1}".format(msg.value(), err.str()))
producer = Producer({'bootstrap.servers': 'localhost:9092'})And finally write some messages to the topic:
points = [
{'lat': '56.265595', 'lon': '12.859432', 'id': '2776420839', 'distance': '1.5', 'altitude': '11.2', 'hr': '88',
'cadence': '0', 'time': '2019-10-09 21:25:25+00:00', 'rawTime': '0'},
{'lat': '56.265566', 'lon': '12.859438', 'id': '2776420839', 'distance': '4.6', 'altitude': '11.3', 'hr': '89',
'cadence': '79', 'time': '2019-10-09 21:25:27+00:00', 'rawTime': '2'},
{'lat': '56.265503', 'lon': '12.859488', 'id': '2776420839', 'distance': '12.2', 'altitude': '11.4', 'hr': '92',
'cadence': '79', 'time': '2019-10-09 21:25:30+00:00', 'rawTime': '5'},
{'lat': '56.265451', 'lon': '12.85952', 'id': '2776420839', 'distance': '18.4', 'altitude': '11.4', 'hr': '97',
'cadence': '83', 'time': '2019-10-09 21:25:32+00:00', 'rawTime': '7'},
{'lat': '56.26558', 'lon': '12.85943', 'id': '2776420839', 'distance': '3.1', 'altitude': '11.2', 'hr': '89',
'cadence': '79', 'time': '2019-10-09 21:25:26+00:00', 'rawTime': '1'}
]
for point in points:
payload = json.dumps(point, ensure_ascii=False).encode('utf-8')
producer.produce(topic='activities-realtime', key=str(point['id']), value=payload, callback=acked)
producer.flush()We can check that those messages have reached the topic by running the following command:
docker exec -it kafka-strava kafka-console-consumer.sh \
--bootstrap-server localhost:9092 \
--topic activities-realtime \
--from-beginning{"lat": "56.265595", "lon": "12.859432", "id": "2776420839", "distance": "1.5", "altitude": "11.2", "hr": "88", "cadence": "0", "time": "2019-10-09 21:25:25+00:00", "rawTime": "0"}
{"lat": "56.265566", "lon": "12.859438", "id": "2776420839", "distance": "4.6", "altitude": "11.3", "hr": "89", "cadence": "79", "time": "2019-10-09 21:25:27+00:00", "rawTime": "2"}
{"lat": "56.265503", "lon": "12.859488", "id": "2776420839", "distance": "12.2", "altitude": "11.4", "hr": "92", "cadence": "79", "time": "2019-10-09 21:25:30+00:00", "rawTime": "5"}
{"lat": "56.265451", "lon": "12.85952", "id": "2776420839", "distance": "18.4", "altitude": "11.4", "hr": "97", "cadence": "83", "time": "2019-10-09 21:25:32+00:00", "rawTime": "7"}
{"lat": "56.26558", "lon": "12.85943", "id": "2776420839", "distance": "3.1", "altitude": "11.2", "hr": "89", "cadence": "79", "time": "2019-10-09 21:25:26+00:00", "rawTime": "1"}
Processed a total of 5 messagesIt’s looking good so far.
Unsorted Table
Now let’s create a real-time table called activities_realtime to ingest the data from that Kafka topic into Pinot.
This table doesn’t specify a sorted column.
{
"tableName": "activities_realtime",
"tableType": "REALTIME",
"segmentsConfig": {
"timeColumnName": "timestamp",
"schemaName": "activities",
"replication": "1",
"replicasPerPartition": "1"
},
"tenants": {
"broker":"DefaultTenant",
"server":"DefaultTenant"
},
"tableIndexConfig": {
"invertedIndexColumns": [],
"rangeIndexColumns": [],
"autoGeneratedInvertedIndex": false,
"createInvertedIndexDuringSegmentGeneration": false,
"sortedColumn": [],
"bloomFilterColumns": [],
"loadMode": "MMAP",
"streamConfigs": {
"streamType": "kafka",
"stream.kafka.topic.name": "activities",
"stream.kafka.broker.list": "kafka-strava:9093",
"stream.kafka.consumer.type": "lowlevel",
"stream.kafka.consumer.prop.auto.offset.reset": "smallest",
"stream.kafka.consumer.factory.class.name": "org.apache.pinot.plugin.stream.kafka20.KafkaConsumerFactory",
"stream.kafka.decoder.class.name": "org.apache.pinot.plugin.stream.kafka.KafkaJSONMessageDecoder",
"realtime.segment.flush.threshold.rows": "5",
"realtime.segment.flush.threshold.time": "24h",
"realtime.segment.flush.segment.size": "100M"
},
"noDictionaryColumns": [],
"onHeapDictionaryColumns": [],
"varLengthDictionaryColumns": [],
"enableDefaultStarTree": false,
"enableDynamicStarTreeCreation": false,
"aggregateMetrics": false,
"nullHandlingEnabled": false
},
"ingestionConfig": {
"batchIngestionConfig": {
"segmentIngestionType": "APPEND",
"segmentIngestionFrequency": "DAILY"
},
"transformConfigs": [
{"columnName": "location", "transformFunction": "toSphericalGeography(stPoint(lon, lat))" },
{"columnName": "timestamp", "transformFunction": "FromDateTime(\"time\", 'yyyy-MM-dd HH:mm:ssZ')" }
]
},
"metadata": {}
}|
Warning
|
The |
We can create a table by running the following command:
docker exec -it pinot-controller-strava-realtime bin/pinot-admin.sh AddTable \
-tableConfigFile /config/table-realtime.json \
-execOnce we create this table, Pinot will start ingesting data from the Kafka topic. We can check which segments have been created by navidating to http://localhost:9000/#/tenants/table/activities_realtime_REALTIME. You should see something like the following:
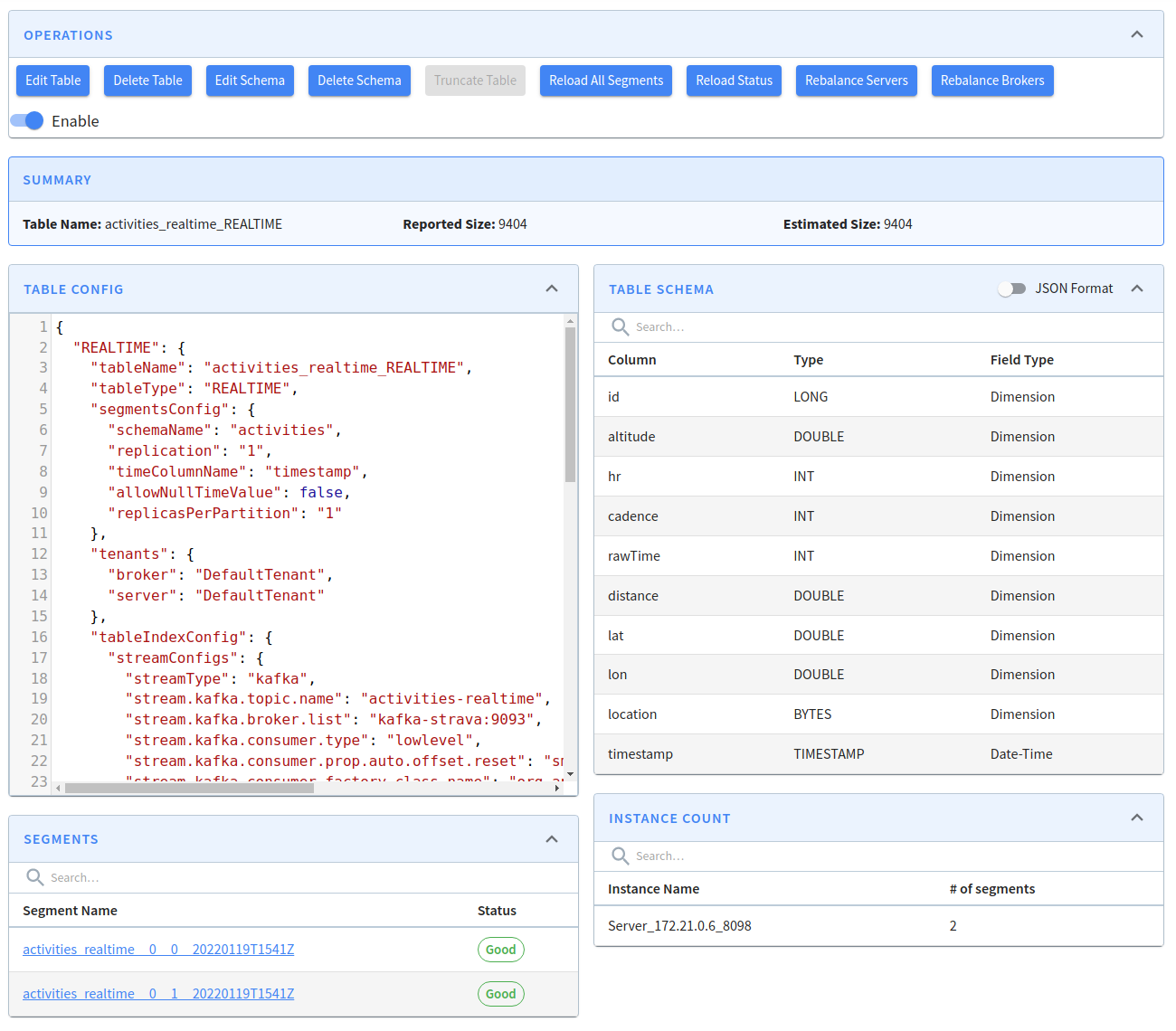
If we click on the first segment, we’ll see the following:
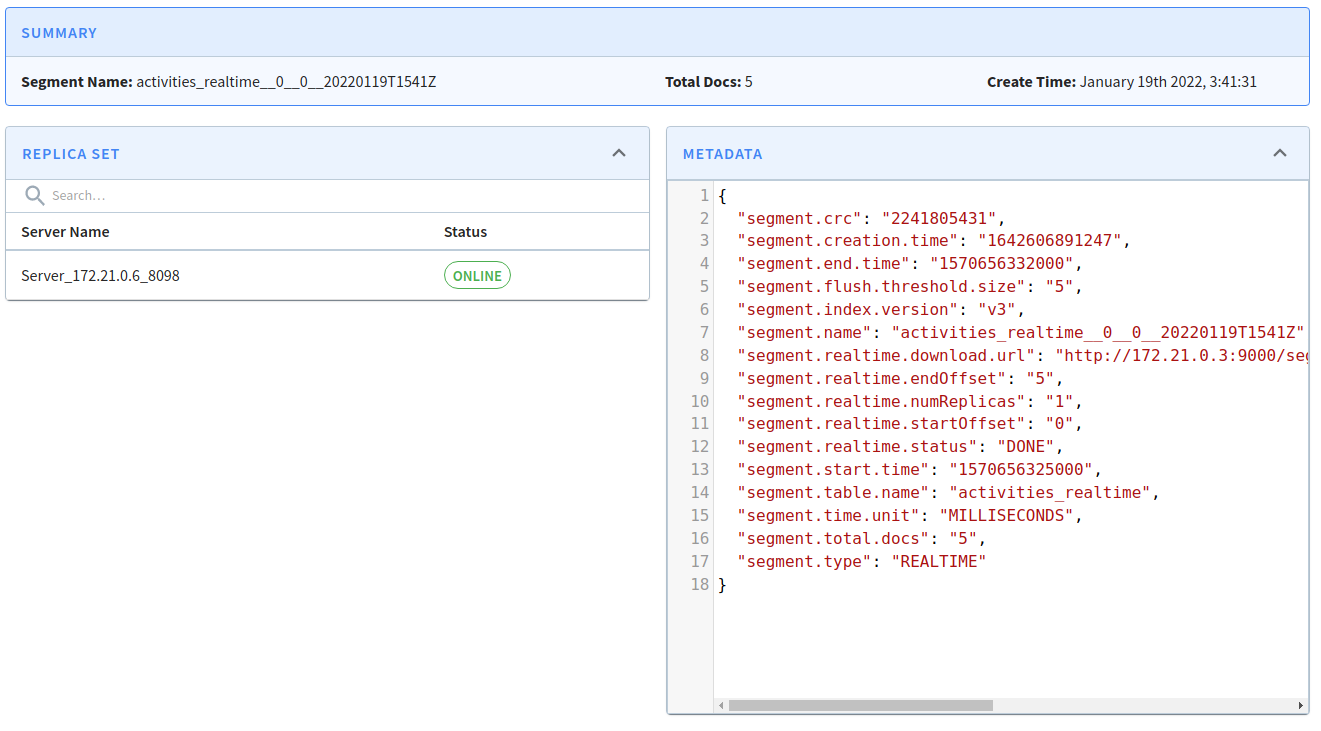
We can see that this segment has been committed by looking at the segment.realtime.status property on the right hand side.
The segment.total.docs property tells us that this segment contains 5 documents.
Now let’s go back and then click the other segment. If we do that we’ll see the following:
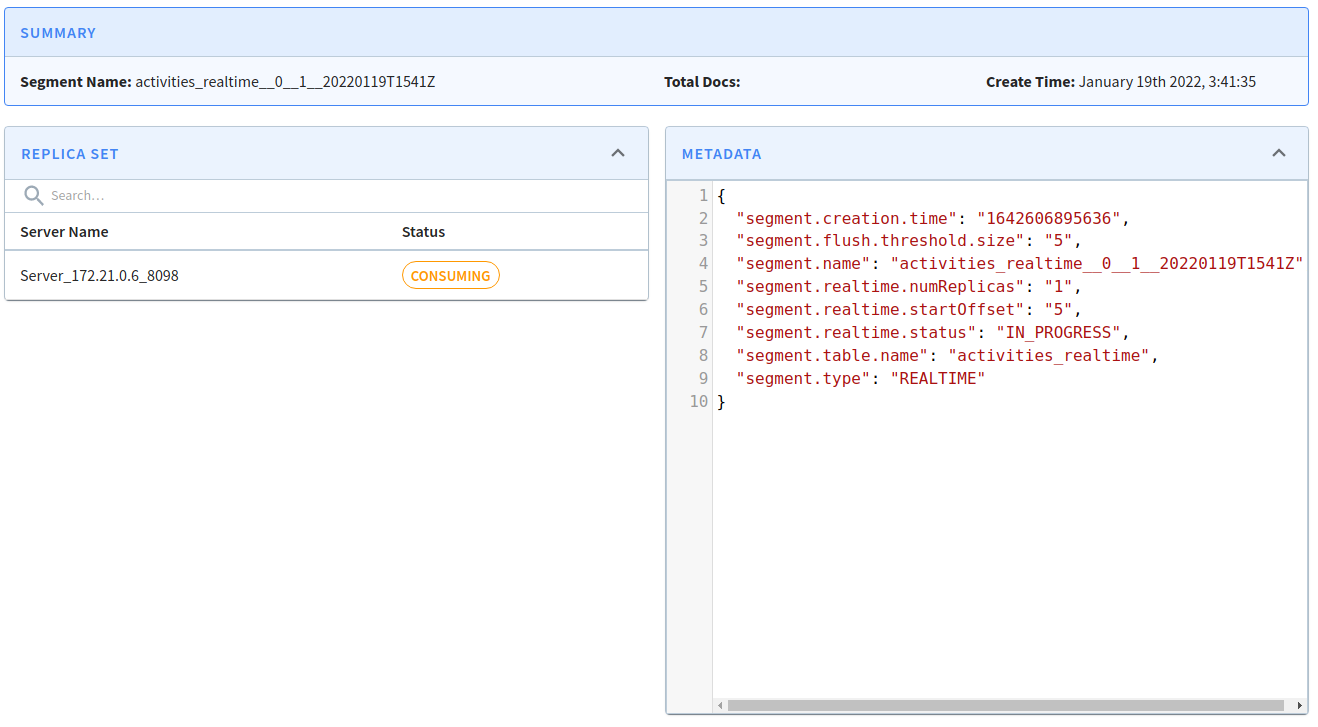
This one is IN_PROGRESS and if add some more messages to the Kafka topic they will go into this segment.
Now we’re going to check on the sorted status of the columns for all committed segments i.e segment activities_realtime01__20220119T1541Z in this case.
First let’s collect all the columns in the activities schema:
export queryString=`curl -X GET "http://localhost:9000/schemas/activities" -H "accept: application/json" 2>/dev/null |
jq -r '[.dimensionFieldSpecs,.dateTimeFieldSpecs | .[] | .name ] | join("&columns=")'`And now let’s call the getServerMetaData endpoint to return the segments for the activities_realtime table and filter the response to get the segment name, input file, and column names with sorted status:
curl -X GET "http://localhost:9000/segments/activities_realtime/metadata?columns=${queryString}" \
-H "accept: application/json" 2>/dev/null |
jq -c '.[] | select(.columns != null) | {
segment: .segmentName,
columns: .columns | map({(.columnName): .sorted})
}'|
Note
|
To refresh our minds, the data in the table was imported in the order shown in the table below:
|
If we run this command, we’ll see the following output:
{
"segment": "activities_realtime__0__0__20220119T1541Z",
"importedFrom": null,
"columns": [
{"altitude": false},
{"distance": false},
{"hr": false},
{"lon": false},
{"cadence": false},
{"rawTime": false},
{"location": false},
{"id": true},
{"lat": false},
{"timestamp": false}
]
}From the output we can see that almost all of the columns aren’t sorted.
The only sorted column is id and that’s because we only have one unique value in that column.
Sorted Table
Now let’s create a real-time table called activities_realtime_sorted that specifies timestamp as a sorted column.
{
"tableName": "activities_realtime_sorted",
"tableType": "REALTIME",
"segmentsConfig": {
"timeColumnName": "timestamp",
"schemaName": "activities",
"replication": "1",
"replicasPerPartition": "1"
},
"tenants": {
"broker":"DefaultTenant",
"server":"DefaultTenant"
},
"tableIndexConfig": {
"invertedIndexColumns": [],
"rangeIndexColumns": [],
"autoGeneratedInvertedIndex": false,
"createInvertedIndexDuringSegmentGeneration": false,
"sortedColumn": ["timestamp"],
"bloomFilterColumns": [],
"loadMode": "MMAP",
"streamConfigs": {
"streamType": "kafka",
"stream.kafka.topic.name": "activities",
"stream.kafka.broker.list": "kafka-strava:9093",
"stream.kafka.consumer.type": "lowlevel",
"stream.kafka.consumer.prop.auto.offset.reset": "smallest",
"stream.kafka.consumer.factory.class.name": "org.apache.pinot.plugin.stream.kafka20.KafkaConsumerFactory",
"stream.kafka.decoder.class.name": "org.apache.pinot.plugin.stream.kafka.KafkaJSONMessageDecoder",
"realtime.segment.flush.threshold.rows": "5",
"realtime.segment.flush.threshold.time": "24h",
"realtime.segment.flush.segment.size": "100M"
},
"noDictionaryColumns": [],
"onHeapDictionaryColumns": [],
"varLengthDictionaryColumns": [],
"enableDefaultStarTree": false,
"enableDynamicStarTreeCreation": false,
"aggregateMetrics": false,
"nullHandlingEnabled": false
},
"ingestionConfig": {
"batchIngestionConfig": {
"segmentIngestionType": "APPEND",
"segmentIngestionFrequency": "DAILY"
},
"transformConfigs": [
{"columnName": "location", "transformFunction": "toSphericalGeography(stPoint(lon, lat))" },
{"columnName": "timestamp", "transformFunction": "FromDateTime(\"time\", 'yyyy-MM-dd HH:mm:ssZ')" }
]
},
"metadata": {}
}We can create a table by running the following command:
docker exec -it pinot-controller-strava-realtime bin/pinot-admin.sh AddTable \
-tableConfigFile /config/table-realtime-.json \
-execWe can call the getSegments endpoint to check which segments have been created for this table:
curl -X GET "http://localhost:9000/segments/activities_realtime_sorted" -H "accept: application/json" 2>/dev/null[
{
"REALTIME": [
"activities_realtime_sorted__0__0__20220120T0952Z",
"activities_realtime_sorted__0__1__20220120T0952Z"
]
}
]We can then call the getSegmentMetadata endpoint to return the metadata for each of these segments:
segments=`curl -X GET "http://localhost:9000/segments/activities_realtime_sorted" \
-H "accept: application/json" 2>/dev/null |
jq -r '.[] | .REALTIME[]'`
for segment in ${segments}; do
curl -X GET "http://localhost:9000/segments/activities_realtime_sorted/${segment}/metadata" \
-H "accept: application/json" 2>/dev/null | jq '.'
done{
"segment.crc": "3864673434",
"segment.creation.time": "1642672360783",
"segment.end.time": "1570656332000",
"segment.flush.threshold.size": "5",
"segment.index.version": "v3",
"segment.name": "activities_realtime_sorted__0__0__20220120T0952Z",
"segment.realtime.download.url": "http://172.21.0.3:9000/segments/activities_realtime_sorted/activities_realtime_sorted__0__0__20220120T0952Z",
"segment.realtime.endOffset": "5",
"segment.realtime.numReplicas": "1",
"segment.realtime.startOffset": "0",
"segment.realtime.status": "DONE",
"segment.start.time": "1570656325000",
"segment.table.name": "activities_realtime_sorted",
"segment.time.unit": "MILLISECONDS",
"segment.total.docs": "5",
"segment.type": "REALTIME"
}
{
"segment.creation.time": "1642672361525",
"segment.flush.threshold.size": "5",
"segment.name": "activities_realtime_sorted__0__1__20220120T0952Z",
"segment.realtime.numReplicas": "1",
"segment.realtime.startOffset": "5",
"segment.realtime.status": "IN_PROGRESS",
"segment.table.name": "activities_realtime_sorted",
"segment.type": "REALTIME"
}From this output we learn that segment activities_realtime_sorted0020220120T0952Z has already been committed and segment activities_realtime_sorted0120220120T0952Z is still in progress.
Any new records will be added to segment activities_realtime_sorted01__20220120T0952Z.
Now let’s check on the sorted status of columns in these segments using the getServerMetaData endpoint:
curl -X GET "http://localhost:9000/segments/activities_realtime_sorted/metadata?columns=${queryString}" \
-H "accept: application/json" 2>/dev/null |
jq -c '.[] | select(.columns != null) | {
segment: .segmentName,
columns: .columns | map({(.columnName): .sorted})
}'|
Note
|
The table below shows the effective order of the data in the segment when it was committed:
|
If we run this command, we’ll see the following output:
{
"segment": "activities_realtime_sorted__0__0__20220120T0952Z",
"columns": [
{"altitude": true},
{"distance": true},
{"hr": true},
{"lon": false},
{"cadence": true},
{"rawTime": true},
{"location": false},
{"id": true},
{"lat": false},
{"timestamp": true}
]
}Now the timestamp field is sorted, which is what we would expect, along with a bunch of other fields as well.
It’s unlikely that any of the other fields would remain sorted if we we imported any records. distance and rawTime are correlated with timestamp within a single activity, but if a segment contained multiple contained multiple activities that correlation would be lost.
Conclusion
That’s the end of this mini blog series about Pinot’s sorted indexes. Hopefully it all made sense, but if not feel free to ask any questions on the Pinot Community Slack.
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.