
python-youtube: Retrieving multiple pages using page token
I’ve been playing around with the YouTube API to analyse comments on YouTube videos and needed to use pagination to get all the comments. In this blog post, we’ll learn how to do that.
But before we do anything, you’ll need to go to console.developers.google.com, create a project and enable YouTube Data API v3.
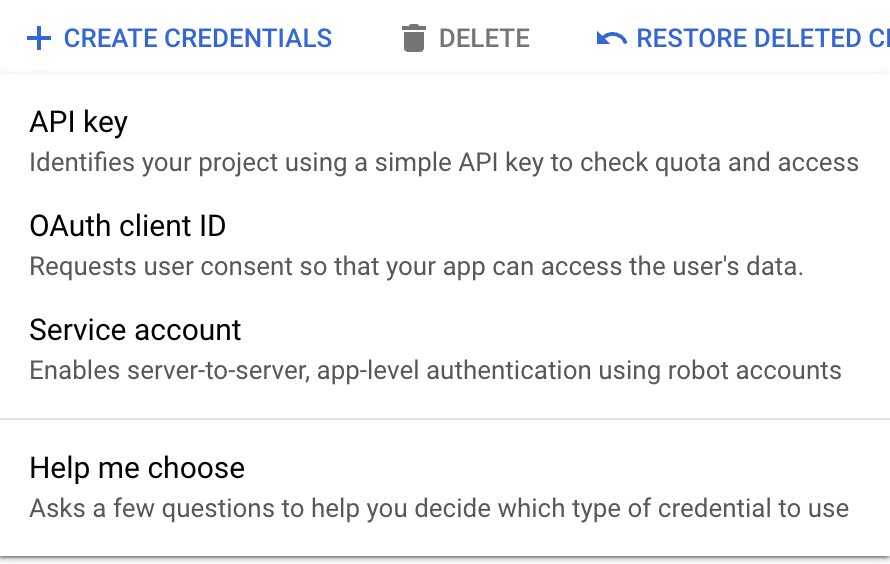
Once you’ve done that, create an API key.
Create an environment variable that contains your API key:
export YOUTUBE_API_KEY="your-api-key-goes-here"Now we’re ready to go!
You can call the YouTube API via HTTP requests, but I find it’s slightly easier to use the python-youtube library, which we can install like this:
pip install python-youtubeLaunch a Python REPL or Jupyter Notebook and add the following imports:
from pyyoutube import Api
import osNext, initialise the API:
API_KEY = os.environ.get("YOUTUBE_API_KEY")
api = Api(api_key=API_KEY)And now we need to choose a video! I really like Matt Williams' YouTube channel for learning about all things related to Ollama, so let’s pick one of his videos.
The video ID for this video is NNBWmIve3fQ, which we can plug into the API like this:
VIDEO_ID = 'NNBWmIve3fQ'
ct_by_video = api.get_comment_threads(
video_id=VIDEO_ID,
count=10
)
ct_by_videoCommentThreadListResponse(kind='youtube#commentThreadListResponse')We can go down into the CommentThreadListResponse to find the top-level comments like this:
comments = [
item.snippet.topLevelComment.snippet.textDisplay
for item in ct_by_video.items
]
comments[
'I'd love to seereal metrics - speed improvement, code quality, etc? Also, am I using up 4g for each application/plugin that uses the same model?',
'Hi. I actually play around with Ollama in vs code. So I have a question. What is the Llama coder extension for? I installed it, but couldn't figure out what it does our how to use it. Maybe i configured something wrong? But from the documentation it's also not clear how to proberly use it. So now I don't know if I does something wrong 😢',
'Can you make a video on Egpu settings and using Ollama to use it, as a perfered set up?',
'I tested pre-Release version of Continue extension for VS Code with Ollama and set deep seek as the model. <br>Amazing! I can’t believe I can use such powerful AI autocomplete in my VSCode for free…<br><br>For Free! And it works so well',
'Before running the JavaScript code you need to run $ ollama run <some model> though, right?',
'wft why white theme',
'The age of cr@ppy software, made with the help of clueless and irresponsible AIs is coming, hold on to your chairs!',
'There is a tremendous ammount of work Ollama team is doing <3 <br>Really awesome work and ollama works like a charm. This definitely motivates me to "go beyond, plus ultraaaa"',
'<a href="https://www.youtube.com/watch?v=NNBWmIve3fQ&t=170">2:50</a>: Where can I find it for vscodium?',
'hey, cool video! could you maybe do a video about mixtral8x7b?'
]So that’s the first 10 comments, but what if we want to get more?
It turns out the CommentThreadListResponse has a nextPageToken attribute, which we can use to get the next pages.
ct_by_video.nextPageToken'Z2V0X25ld2VzdF9maXJzdC0tQ2dnSWdBUVZGN2ZST0JJRkNJa2dHQUFTQlFpSUlCZ0FFZ1VJblNBWUFSSUZDSWNnR0FBU0JRaW9JQmdBR0FBaURRb0xDSldXOWEwR0VLaUUtQWs='Let’s use that to get some more comments:
next_ct_by_video = api.get_comment_threads(
video_id=VIDEO_ID,
count=10,
page_token=ct_by_video.nextPageToken
)
[
item.snippet.topLevelComment.snippet.textDisplay
for item in next_ct_by_video.items
][
'I tried llama coder not worked <br>Continue worked. Others are flaky at best. Thanks for videos i will look more extensions and models for my need.<br><br>If you have any idea that's great <br>Q. Llama coder always said model not available but it is their and continue can use it and respond me back',
'great content, which is the font used in vs code?',
'my system cant handle it and it would just crash',
'how do I do it if Ollama is on my LAN?',
'Windows users cry in the corner.',
'I have already paid copilot for 1 year….',
'okay okay so living in the wilderness is fine but of course:<br><br>mother_natures_beauty && awe < Python',
'Great content! So much here and didn’t even feel rushed in the short amount of time to cover all this.',
'Great video. I’ve found those two extensions to be the best as well. The small, fast model for the autocomplete. The bigger better model for Continue. Deepseek for both, but I havent tried Codellama. Complete game changer for offline coding!',
'Greetings from Victoria!'
]We can keep doing that until we get to the last page, at which point nextPageToken won’t return a value.
It’s probably best to create a function to handle the paging for us and return all the comments:
def get_all_comment_threads(api, video_id, per_page=10):
threads = []
token = None
while True:
response = api.get_comment_threads(
video_id=video_id,
count=per_page,
page_token=token
)
threads.append(response)
token = response.nextPageToken
if not token:
break
return threadsWe can call the function like this:
threads = get_all_comment_threads(api, VIDEO_ID)
threads[
CommentThreadListResponse(kind='youtube#commentThreadListResponse'),
CommentThreadListResponse(kind='youtube#commentThreadListResponse'),
CommentThreadListResponse(kind='youtube#commentThreadListResponse'),
CommentThreadListResponse(kind='youtube#commentThreadListResponse')
]And then extract all the comments from the threads like this:
all_comments = [
item.snippet.topLevelComment.snippet.textDisplay
for t in threads for item in t.items
]
len(all_comments)39So there are 39 top-level comments on this video, although there are many many more if we were to include replies.
And just for fun, let’s try it on one of Matt Berman’s videos:
threads = get_all_comment_threads(api, "KzxR2Vcr9CM", per_page=100)
all_comments = [
item.snippet.topLevelComment.snippet.textDisplay
for t in threads for item in t.items
]
len(all_comments), all_comments[:10](
356,
[
'Will OpenAI or NVIDIA reach AGI first?',
'your current testing is very weak, you should improve your methods and keep evolving your methods as tooling improve, e.g. tests requiring some graphics like "write the formula for the Möbius strip and draw it" (ParametricPlot3D[{Cos[t] + s Sin[t/2] Cos[t], Sin[t] + s Sin[t/2] Sin[t], s Cos[t/2]}, {t, 0, 2 Pi}, {s, -0.5, 0.5}, Mesh -> None, PlotStyle -> Directive[Opacity[0.6], Blue], Axes -> False]<br>). i am willing to bet that traditional interfaces are not going anywhere, though they change form somewhat, peoples need to be able to get their hands on a project, a pocket computer is not a desktop computer, they serve very different purposes for most people. Also i am willing to bet that neural link will fail, i am seriously persuaded the technology will become very unpopular.',
'your title devalues the content, seriously mate, all you AI guys have got to stop saying 'shocked', 'stunned', speechless bs, no informed person is shocked stunned or speechless about this exponential progress, you;re making you vids look like a late night infomercial. be serious, these are serious times',
'nV is a piece of sh company stealing ideas, code and work since day 0. AI is a joke without army of engineers babysitting the models<br>prophecy says without opensourcing everything all code, apps and hardware will die',
'Why do you and Wes Roth produce the exact same thumbnails with the exact same "SHOCKS THE INDUSTRY" titles in every single video you release?<br>You guys both produce stellar content, but i'm so utterly tired of seeing the exact same over-hyping clickbait titles in every single video either of you post (and its strange they're all so identical).<br>Yes, AI developments are astonishing, and worthy of hype. But can we please tone down the nonstop identical titles and focus on the news?',
'I think the issue with context window is caused by having a tldr/summary at the end, as well as an introduction giving context',
'I think it's perfectly feasible that LLMs take us all the way to AGI. There are better architectures we explore after we get there (human brain, proof by existence), which will likely push us into ASI fairly quickly after that.',
'Our brains learn more with little data because they are already the trained foundation model, evolved by natural selection -- trained on billions/trillions of iterations of real world physical data (that didn't have to be simulated).',
'That's not AI, that's crap. Human brain consumes only 100W of power at peak, learns instantly, doesn't need a billion-dollar worth supercomputer to work, doesn't require a team of scientists to be trained, doesn't need a team of low-paid monkeys to correct its errors and jury-rig the results to fit them to the task. And it almost fits in your pocket.',
'I think you should have mentioned where Gemini has gone off the rails and erased history. This is why we need open source.'
]
)About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.