
Nygard Big Data Model: The Investigation Stage
Earlier this year Michael Nygard wrote an extremely detailed post about his experiences in the world of big data projects and included in the post was the following diagram which I’ve found very useful.
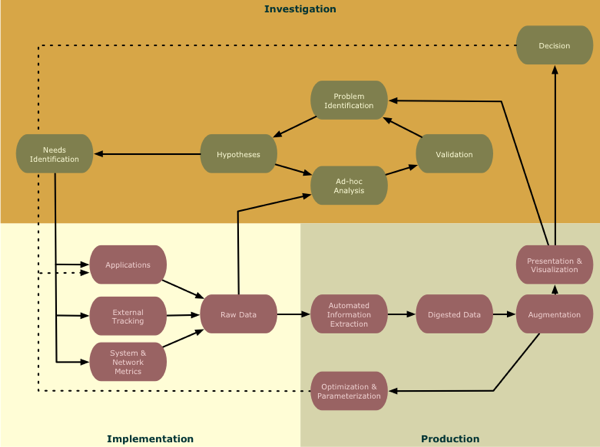
Nygard’s Big Data Model (shamelessly borrowed by me because it’s awesome)
Ashok and I have been doing some work in this area helping one of our clients make sense of and visualise some of their data and we realised retrospectively that we were very acting very much in the investigation stage of the model.
In particular Nygard makes the following suggestions about the way that we work when we’re in this mode:
We don’t want to invest in fully automated machine learning and feedback. That will follow once we validate a hypothesis and want to integrate it into our routine operation. Ad-hoc analysis refers to human-based data exploration. This can be as simple as spreadsheets with line graphs...the key aspect is that most of the tools are interactive. Questions are expressed as code, but that code is usually just "one shot" and is not meant for production operations.
In our case we weren’t doing anything as complicated as machine learning - most of our work was working out the relationships between things, how best to model those and what visualisations would best describe what we were seeing.
We didn’t TDD any of the code, we copy/pasted a lot and when we had a longer running query we didn’t try and optimise it there and then, instead we ran it once, saved the results to a file and then used the file to load it onto the UI.
We were able to work in iterations of 2/3 hours during which we tried to answer a question (or more than one if we had time) and then showed our client what we’d managed to do and then decided where we wanted to go next.
To start with we did all this with a subset of the actual data set and then once we were on the right track we loaded in the rest of the data.
We can easily get distracted by the difficulties of loading large amounts of data before checking whether what we’re doing makes sense.
We iterated 4 or 5 different ideas before we got to one that allowed us to explore an area which hadn’t previously been explored.
Now that we’ve done that we’re rewriting the application from scratch, still using the same ideas as from the initial prototype, but this time making sure the queries can run on the fly and making the code a bit closer to production quality!
We’ve moved into the implementation stage of the model for this avenue although if I understand the model correctly, it would be ok to go back into investigation mode if we want to do some discovery work with others parts of the data.
I’m probably quoting this model way too much to people that I talk to about this type of work but I think it’s really good so nice work Mr Nygard!
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.