
LLaVA 1.5 vs. 1.6
LLaVA (or Large Language and Vision Assistant), an open-source large multi-modal model, just released version 1.6. It claims to have improvements over version 1.5, which was released a few months ago:
Increasing the input image resolution to 4x more pixels. This allows it to grasp more visual details. It supports three aspect ratios, up to 672x672, 336x1344, 1344x336 resolution.
Better visual reasoning and OCR capability with an improved visual instruction tuning data mixture.
Better visual conversation for more scenarios, covering different applications. Better world knowledge and logical reasoning.
Efficient deployment and inference with SGLang.
Both the initial and new versions are available on Ollama, so I thought I’d give them a try on some of my images to see how they get on.
|
I’ve created a video showing how to do this on my YouTube channel, Learn Data with Mark, so if you prefer to consume content through that medium, I’ve embedded it below: |
If you want to follow along, you’ll need to install Ollama, launch Ollama (ollama serve), and then pull down both models:
ollama pull llava:7b-v1.5-q4_0
ollama pull llava:v1.6Now let’s try out the models.
A photo of me
We’ll start with the following image of me looking through a magnifying glass.

Let’s create a chat session with the 1.5 version of LLaVA:
ollama run llava:7b-v1.5-q4_0We can then ask it to describe the image:
"Can you describe this image? ./images/image.png"Added image './images/image1.png'
The image depicts a bald man wearing glasses, holding up a magnifying glass to his eye. He is standing in front of a black background, possibly to focus on the
subject matter being observed through the lens of the magnifying glass. His attentive gaze suggests that he might be examining an object or studying something in detail.One neat recent feature of Ollama is that we can switch to another model from within the session by calling the load command.
So to use the v1.6 model, we would call the following:
/load llava:v1.6Loading model 'llava:v1.6'And if we ask this model to describe the image, we’ll see the following output:
In the image, there is a man who appears to be in his middle years. He has a bald head and is wearing glasses with black frames and a thin black strap. The man is holding up what looks like a magnifying glass over his eye, as if examining something closely. He has a slight smile on his face and is looking directly at the camera, creating an engaging perspective.
The man is dressed in a casual manner, with a white t-shirt adorned with a small pattern and a pair of dark pants. His stance is relaxed, suggesting he might be in a lighthearted or informal setting.
Behind him, there's a plain black background that contrasts with the man and draws attention to him. The image does not contain any text or additional objects. The focus is solely on the man and his interaction with the magnifying glass.1.6 gives a more detailed answer, but I think it’s more or less the same description as 1.5 gave.
Ollama Python
For the rest of the examples, we’re going to use the Ollama Python library, which we can install by running the following:
pip install ollamaNext, we’ll run the following in a Jupyter notebook or from a Python REPL:
import ollama
def generate(model, image, prompt):
stream = ollama.generate(
model=model,
prompt=prompt,
images=[image],
stream=True
)
response = ""
for chunk in stream:
response += chunk['response']
print(chunk['response'], end='', flush=True)
print("")
return responseCaptioning an image
Next, we’re going to ask models to come up with a caption for the following image:

We can do this by running the following code:
image = "images/image2.png"
prompt = "Create a caption for this image"
for model in ['llava:7b-v1.5-q4_0', 'llava:v1.6']:
print(f"Model: {model}")
generate(model, image, prompt)Model: llava:7b-v1.5-q4_0
A blue brick wall with a white arrow pointing to the left.
Model: llava:v1.6
"A playful twist on direction, with a blue wall providing the backdrop."If we update the prompt to include the word 'creative', like this:
image = "images/image2.png"
prompt = "Create a creative caption for this image"
for model in ['llava:7b-v1.5-q4_0', 'llava:v1.6']:
print(f"Model: {model}")
generate(model, image, prompt)We get a slightly better output:
Model: llava:7b-v1.5-q4_0
"A blue arrow pointing the way, guiding us on our journey."
Model: llava:v1.6
"Guiding the way to endless possibilities: a sign pointing towards an unknown adventure."There’s not much in it, but it seems to me that version 1.6 has 'understood' the prompt a bit better.
Reading a banner image
Next up, let’s see if the models can read the text from a banner image of one of my blog posts.

We’ll use the following prompt:
image = "images/image3.png"
prompt = "What text is written on this image?"
for model in ['llava:7b-v1.5-q4_0', 'llava:v1.6']:
print(f"Model: {model}")
generate(model, image, prompt)I ran this a few times because it was giving different answers each time. Here’s the output for version 1.5:
Model: llava:7b-v1.5-q4_0
5 Ways to Use AI in Your Business
Running a large language model locally on my laptop.
"Hugging Face"And 1.6:
Model: llava:7b-v1.5-q4_0
The text on the image reads: "HUGGING FACE - RUNNING A LARGE LANGUAGE MODEL LOCALLY ON MY LAPTOP"
The text on the image reads: "Hugging Face" followed by a description of how to use Hugging Face for running a large language model locally on one's laptop.
The text on the image reads: "Hugging Face Running a Large Language Model Locally On My Laptop"It’s by no means perfect, but I think version 1.6 wins this one.
Extracting code from an image
But can it extract code from an image? These days lots of people create LinkedIn posts with code on images and I’d quite like to get that code and run it locally. Perhaps LLaVA can help out here. We’re going to use the following image:
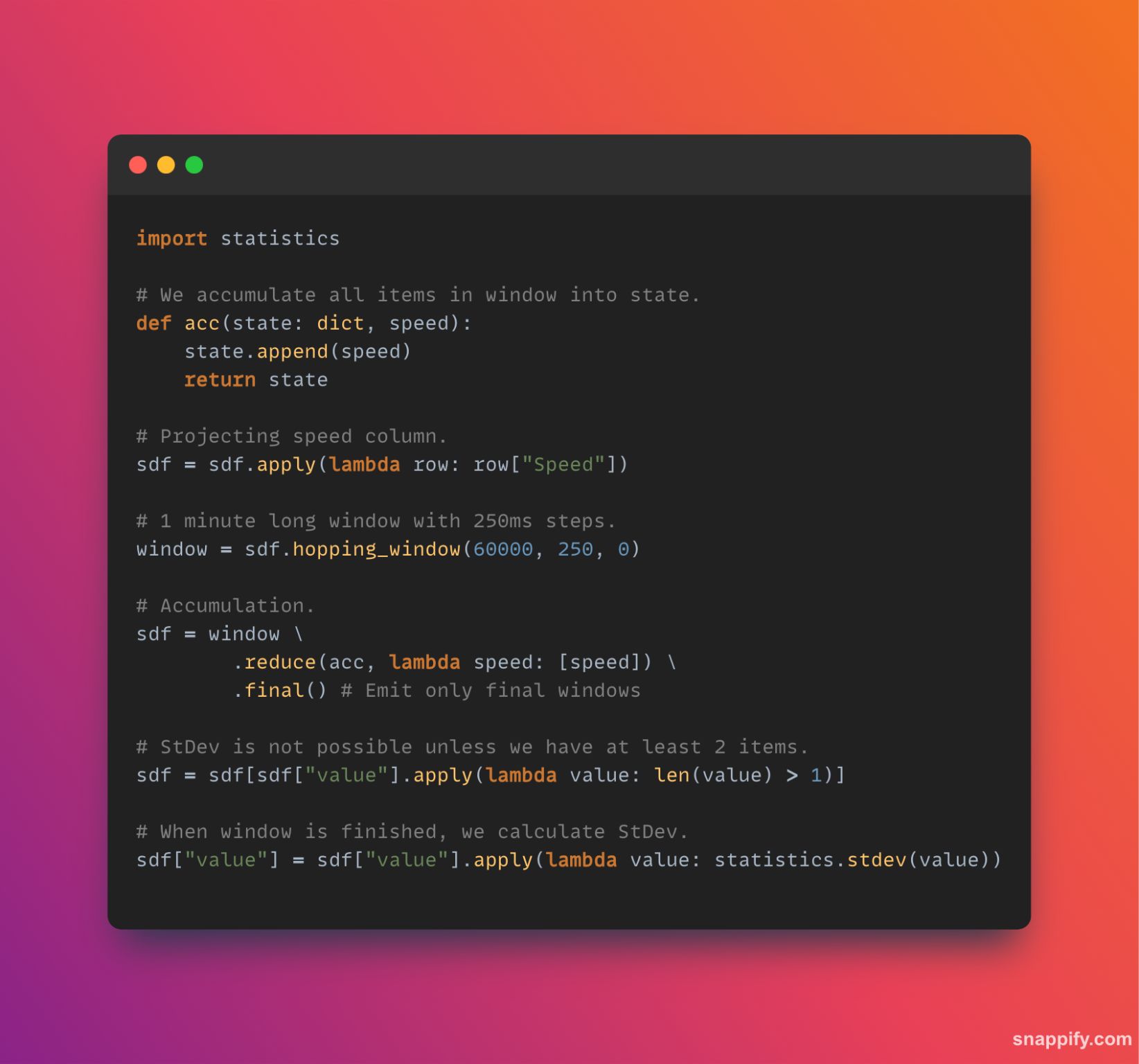
And we’ll use the following prompt:
image = "images/image4.png"
prompt = "Extract the code from this image"
for model in ['llava:7b-v1.5-q4_0', 'llava:v1.6']:
print(f"Model: {model}")
generate(model, image, prompt)And here’s how the models fared, starting with 1.5:
Model: llava:7b-v1.5-q4_0
```sql
a = A + 1
b = B + 1
c = C + 1
d = D + 1
if (a > b and a > c) then begin
RP_RPT("A is greater than B but less than C")
end if
if (b > a and b > c) then begin
RP_RPT("B is greater than A but less than C")
end if
if (c > a and c > b) then begin
RP_RPT("C is greater than A and B")
end if
if (a = b and b = c) then begin
RP_RPT("A,B,C are equal")
end if
if (a < b and a < c) then begin
RP_RPT("A is less than B but greater than C")
end if
if (b < a and b < c) then begin
RP_RPT("B is less than A but greater than C")
end if
if (c < a and c < b) then begin
RP_RPT("C is less than A but greater than B")
end if
if (a > b or not(b = c)) then begin
RP_RPT("A,B are not equal")
end if
if (a < b and a <= C) then begin
RP_RPT("A is less than B but greater than or equal to C")
end if
if (b >= A and b <= C) then begin
RP_RPT("B is within the range of A & C")
end if
if (c > A and c <= B) then begin
RP_RPT("C is within the range of A & B")
end if
end if
if (A = -1024 or B = -1024 or C = -1024) then begin
RP_RPT("A,B,C are all equal to the value of -1024")
end if
if (D >= A + B + C and D <= 2**31 - 1) then begin
RP_RPT("D is within the range of A+B+C")And now 1.6
Model: llava:v1.6
The image contains a screenshot of a computer screen with a code snippet displayed. Here is the extracted code:
```python
import statistics as stats
data = [10, 20, 30, 40, 50]
mean = stats.mode(data)
median = stats.median(data)
stdev = stats.stdev(data)
print('Mean:', mean)
print('Median:', median)
print('Standard Deviation (STDEV):', stdev)
```
This code is written in Python and uses the `statistics` module to calculate the mean, median, and standard deviation of a list of numbers. The list `data` contains five elements, which are then processed using the `mode`, `median`, and `stdev` functions from the `statistics` library.Neither model does a good job when it comes to extracting code.
Understanding a diagram
And we’ll finish off by seeing whether the models can explain this diagram, which shows a relational vs graph approach to modelling a problem.
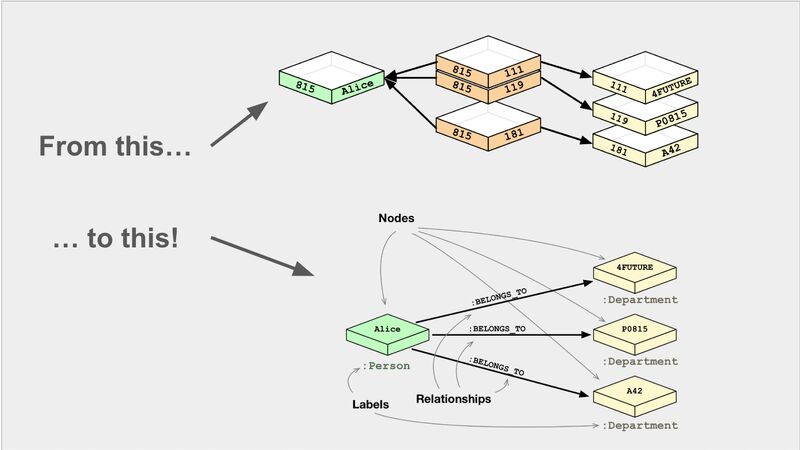
We’ll use this prompt:
image = "images/image5.png"
prompt = "Can you describe this diagram?"
for model in ['llava:7b-v1.5-q4_0', 'llava:v1.6']:
print(f"Model: {model}")
generate(model, image, prompt)Now, let’s see how they get on. First up, 1.5:
Model: llava:7b-v1.5-q4_0
This diagram displays a network of interconnected files, with multiple layers and different shapes. There is a mix of both square and rectangular shapes, which can be seen in various parts of the image. The relationships between these elements are represented by arrows connecting them to one another, indicating that some files are dependent or related to others.
This network diagram appears to represent an intricate system where different files have specific connections with other files within the structure. It provides a visual representation of how these files interact and engage with each other in this complex environment.This doesn’t make a whole lot of sense. Let’s see if 1.6 does any better:
Model: llava:v1.6
The image you've shared is a flowchart that describes a process or workflow, likely from an algorithmic or computational context. Here's a description of the elements in the flowchart:
1. **Start Point**: There are two arrows pointing to a starting point labeled "from this..." suggesting the beginning of a process or algorithm.
2. **Sequence of Operations**: The sequence of operations is depicted by a series of boxes, each representing an action or function within the context of the flowchart. These actions seem to be related to data processing or transformation:
- "Node1" appears to represent some sort of input or initial stage.
- "Node2" and "Node3" seem to be intermediate steps or stages in the process.
- "Node4" represents another significant step or decision point.
- "Node5" is the final node, indicating the completion of the workflow or the output of the process.
3. **Arrows**: The arrows show the flow or direction of the operations. They indicate that the starting point leads to Node1 and then moves through the subsequent nodes until it reaches Node5.
4. **Labels on Nodes**: Each node has labels that are likely to represent actions, functions, or data elements involved in the process. However, without more context, these labels are not clearly defined.
5. **Final Arrow**: There's an arrow from Node5 pointing back to "from this..." which may indicate that the output of Node5 is being fed back into another part of the system.
6. **Connections Between Nodes**: The lines connecting the nodes represent the flow or relationship between them, showing that one node leads to the next in a logical sequence.
7. **Annotations**: There are annotations within the flowchart, but they're not fully legible due to the quality of the image. One can make out phrases like "Node1" and "Node5", indicating the names or identities of these nodes in the workflow.
This type of diagram is commonly used in computer science and software engineering to visualize the steps involved in a process, making it easier to understand and communicate the logic behind a particular algorithm or system.It’s slightly better, but still doesn’t do a good job of explaining the difference between the approaches.
About the author
I'm currently working on short form content at ClickHouse. I publish short 5 minute videos showing how to solve data problems on YouTube @LearnDataWithMark. I previously worked on graph analytics at Neo4j, where I also co-authored the O'Reilly Graph Algorithms Book with Amy Hodler.